

【自己紹介】
#Twitter:@Nurruttan / #YouTube:@Nurruttan
【転職支援サービス】

転職を検討しているデータサイエンティスト向けに【完全無料の】転職支援サービスを実施しています!
詳しくは下記をご覧ください!

【キャリア相談サービス】

キャリアに悩むデータサイエンティスト向けにキャリア相談サービスをやっています!
詳しくは下記をご覧ください!

- 未経験から機械学習の学び方が知りたい
- Pythonでどうやって機械学習を実装するのか知りたい
- 機械学習ってどこからどこまで学ばないといけないの?いろいろあってわかんない!
機械学習ってどうやって学べばいい?Pythonでどうやって実装するの?など悩んでいる人もいるのではないでしょうか?
今回は機械学習を学ぶためにオススメの「[第3版]Python機械学習プログラミング 達人データサイエンティストによる理論と実践」を紹介します。さらに、どのように本書を使って学習すべきかまで詳細に解説します。
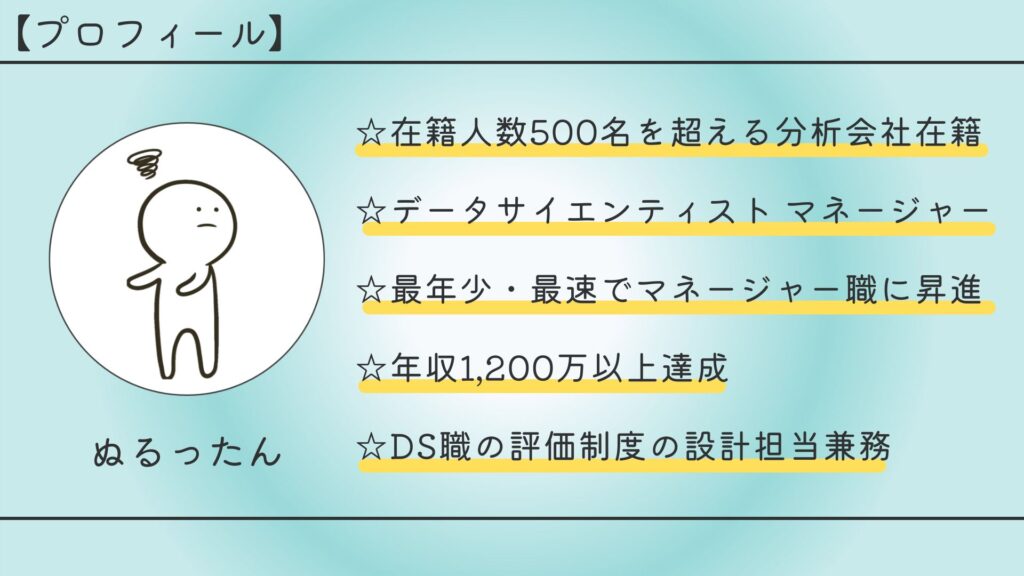
筆者は約500名が在籍する会社で長らくデータサイエンティストとして働いています。いまではデータサイエンティストとして活躍できているものの、スタートは未経験からの転職でした。
実際に筆者が学んだ方法を基に本書を使った「機械学習」の学習方法を解説します。
この記事を読むと、Pythonで機械学習を実装する方法がわかります。さらにこの記事を実践するとデータサイエンティストの基礎スキルが身に付き、データサイエンティストになれる状態になることができます。
未経験からデータサイエンスを学ぶ方法は下記に詳しく解説していますので、ぜひご覧ください。

本記事の結論は下記になります。
- データサイエンティストにとって機械学習は重要?
→超重要!「専門性」を発揮するための必須スキル! - 機械学習ってどうやって実装するの?
→「Python」のライブラリを使えばOK!便利なライブラリが豊富! - 機械学習ってどうやって学ぶの?
→理論を理解する!実装してみる!条件を変えて遊んでみる!の3STEP! - 機械学習を一通り学び終えたらなにをすればいい?
→コンペに参加してみよう!より実践的な経験をしてスキルアップ! - データサイエンティストになろう!スマートなキャリアを作るために行動しよう!
では、本編にいきます。
データサイエンティストにとって機械学習は「専門性」を発揮する必須スキル

データサイエンティストにとって機械学習は身に付けておくべきスキルの一つです。
データ分析だけなら、一般のビジネスマンでもある程度理解される方もいます。しかし、機械学習は専門領域であり、一般のビジネスマンでは理解しきれない範囲です。
つまり、データサイエンティストとしての「専門性」を発揮できる領域です。「専門性」は今後のキャリアにおいて非常に重要となります。
特に、「サイエンス型データサイエンティスト」にとっては自身の価値を決定づけるスキルです。機械学習の知識を武器にキャリアを築いていくこともできます。
機械学習を一通り学べばデータサイエンティストの仲間入りです。
データサイエンティストを志す方には必須スキルであり、学んでいても興味深い領域になります。

機械学習がある程度理解できれば、データサイエンティストの仲間入りだよ。学んでいるうちは気づきにくいけど、十分に「専門性」が身につくよ。
「Python」には機械学習の実装に便利なライブラリが豊富

「Python」には機械学習の実装に便利なライブラリが豊富です。
ライブラリを使うことで、複雑な機械学習のアルゴリズムを比較的容易に実装することが出来ます。
下記に、機械学習を実装する主要なライブラリを紹介します。
- scikit-learn:機械学習の超定番ライブラリ
「回帰」「分類」「クラスタリング」「次元削減」「データの前処理」「モデルの評価と選択」という6つの機能があり、前処理以降のモデル構築プロセスを広範にカバー。 - XGBoost・LightGBM:勾配ブースティング実装の人気ライブラリ
最高精度な機械学習の予測モデルと言えばこれ一択。勾配ブースティング系の実装を容易にできる便利ライブラリ。 - TensorFlow・Keras・PyTorch・Chainer:深層学習系のライブラリ
深層学習(Deeplearning)系のライブラリです。深層学習を容易に実装できます
初心者の方はまずはこれだけ知っていれば十分です。さらに限定すると、まず使えるようになるべきライブラリは「scikit-learn」だけで十分です。
「scikit-learn」の使い方が分かれば、機械学習のライブラリの使い方が理解できるので、他のライブラリを使うハードルがぐっと下がります。
もし、まだPythonのデータ加工を学んでいない方は下記をご覧ください。
⇒Pythonのデータ加工を学んでいない方はコチラ
全部学ぼうとすると効率が悪いよ。まずは、小さく学んで機械学習の感覚を学ぶことが重要だよ。少しずつ知識を身に付けていこうね。
【重要】書籍で学ぶ際に重要なポイント

書籍でプログラミングを学ぶSTEP
書籍でプログラミングを学ぶSTEPは下記のようになります。
- ページを読み進める
- 書いてある実行プログラムを写経(書き写す)してみる
- 実行する
- 成功をよろこぶ
プログラミング初心者は簡単な成功体験を積むのが重要です。こんな僕にもプログラミングができた!と感じてほしいです。
そのため、まずは記載されているプログラムを書き写して実行することから始めましょう。そして、なにより成功をよろこびましょう。重要なのは実行してよろこびを感じることです。
まずは写経して、プログラミングに慣れようね。書いて、実行するんだ。未経験の人は自分書いたプログラムが動いたらよろこびを感じようね。成長を実感することが継続につながるよ。
書籍でプログラミングを学ぶ重要な心構え
書籍でプログラミングを学ぶ重要な心構えは下記です。
- 1時間以上考えて理解できなければ諦める
1時間以上考えて理解できなければあきらめましょう。大丈夫です。
完全に理解しようとしないでください。
ここでは理解しきれずとも、将来的にその要素の存在を思い出せれば大丈夫です。使わなければいけない時に思い出せれば十分です。重要なことはすべてを網羅的に知ることです。
わからないことに時間を使い過ぎてもダメだよ。1時間ほど考えてもわからなかったら飛ばして、次に進もうね。使うときに改めて使えれば問題ないよ。
「達人データサイエンティストによる理論と実践」の使い方
機械学習を学ぶための書籍として、私のオススメは「[第3版]Python機械学習プログラミング 達人データサイエンティストによる理論と実践」です。オススメポイントは下記です。
- サンプルプログラムが豊富にあること!
- 実装だけでなく理論をほどよく解説してくれていること!
- テーマが網羅的で幅広く学べる
まず、サンプルプログラムが豊富で写経しやすいです。これは初心者の学習にとても重要です。
次に、実装だけでなく理論の解説があることです。機械学習のアルゴリズムを理解しながら学習することができます。そして、これが初心者にとってほどよく書かれています。
最後に、テーマが網羅的であることです。データサイエンティストがよく使う機械学習手法が網羅的に掲載されている点がオススメです。
「達人データサイエンティストによる理論と実践」の使って、機械学習を勉強する方法は下記の手順です。
- 理論を理解する
- 実装してみる
- 条件を変えて実行してみる
詳しく解説していきます。
理論を理解する
まずは機械学習の理論を理解しましょう。ライブラリを使って実装する前にまずは「なにが行われているのか?」を理解する必要があります。
重要なポイントは「なんとなく理解する」ことです。機械学習は奥が深いので、深入りしようと思えばいくらでもできてしまいます。
理解の基準としては「まったく機械学習を知らない人にちょっと説明できて、なんだかかっこいいと思われる浅はかな知識」ぐらいのレベル感で初めは十分です。
実際に機械学習を使いながら理解していく方が効率はいいので、まずはざっくりと理論を理解することが重要です。
全部理解しようとしないことが重要だよ。ある程度理解したら次に行こうね。実際に使うタイミングで深く理解することが重要だから、なんとなく理解すれば大丈夫だよ。
実装してみる
理論をある程度理解したら、ライブラリを使って実装してみましょう。
「実装してみようと言われてもわかんないよ!」となると思いますが、大丈夫です。まずは、書籍に書いてあるサンプルプログラムを写経(書き写す)してみましょう。
プログラムに関しては読んでわかった気になるのは絶対にNGです。実際に自身の手で書いてみないとわからないことが多くあります。全く同じことを書いたつもりでも、絶対にエラーが発生します。
このエラーの積み重ねが自身の血肉になり、スキルの上達につながるので必ず自分の手で動かしてみましょう。
プログラミングは読んで身に付くことはないよ。必ず自分で書いて身に付くからね。まずは、写経してみて実行してね。自分が書いたプログラムが動くとうれしいからね。
少し条件を変えて実行してみよう
写経が無事に終わって実行ができたら、条件を少しだけ変えて実行してみましょう。条件を少し変えて実行することで「なにを変えたらなにが変わるの?」がわかります。
条件の変え方はいろいろありますが、一番簡単なのは「データを変えてみること」です。
例えば、入力するデータを少しだけ削ってみたり、数行だけ全部0にしてみたり。
少しデータを変えて、どのような結果になる確認してみましょう。下記のような感じです。
- データを少しだけ変えてみる
- 実行してみる
- 結果をみてみる(予測精度を確認する)
- また、データを少しだけ変えてみる ・・・
実際にやってみるとデータを少し変えただけで精度が落ちたりすることを実感することができると思います。このプロセスを繰り返すことでデータ加工の復習にもなります。
これをやると機械学習の実装におけるデータ加工の重要性がわかるはずです。
データ加工の重要性を経験・実感できると、もはや実務経験がないだけのデータサイエンティストに成長できます。
機械学習におけるデータ加工の重要性がわかるよ。データが汚いと機械学習もうまく機能しないんだ。実践してみて実感することが大事だよ。
「達人データサイエンティストによる理論と実践」の絶対に学ぶべき章

絶対に学ぶべき章について解説をします。下記になります。
- 第3章 分類問題―機械学習ライブラリscikit-learnの活用
- 第4章 データ前処理―よりよいトレーニングセットの構築
- 第6章 モデルの評価とハイパーパラメータのチューニングのベストプラクティス
- 第7章 アンサンブル学習―異なるモデルの組み合わせ
- 第10章 回帰分析―連続値をとる目的変数の予測
データサイエンティストの業務で汎用的によく使うテーマを厳選しています。
どのような企業に入社するかによって必要なスキルは変わりますが、どこにいっても使う可能性が高いテーマを優先的に学習しましょう。
下記、詳細です。
第3章 分類問題―機械学習ライブラリscikit-learnの活用
まずは「scikit-learn」の基礎を学びます。この章では機械学習における「分類」を学びます。機械学習の考え方、「scikit-learn」の使い方の基礎を学ぶ位置づけと捉えてよいでしょう。
美しいグラフも出てくるので、データ分析の可能性を感じる章になります。
第4章 データ前処理―よりよいトレーニングセットの構築
「データの前処理」について学びます。一部「データ加工」と重複する内容が出てきますが、本書では機械学習に入力する前提での前処理という観点で書かれています。
データを分割する理由などもあわせて学ぶことができ、機械学習活用のためのデータ加工が理解できます。
第5章 次元削減でデータを圧縮する
データ圧縮について学びます。データの情報量を残しながらデータを小さくする方法を学びます。少しテクニカルな内容ですが、重要度は高いです。
「莫大なデータがある際にいかに効率よく機械学習を活用するか?」という実務上でよく発生する課題に有用な知識を学べます。
第6章 モデルの評価とハイパーパラメータのチューニングのベストプラクティス
機械学習モデルのよしあしを検証する方法・考え方について学びます。作ったものをどう評価して、どう改善していくかを理解します。
機械学習モデルの精度をあげるために必須な知識を学べる章であり、ここが理解できていないと機械学習の精度をよくすることはできません。深く理解しておくべき内容です。
第7章 アンサンブル学習―異なるモデルの組み合わせ
アンサンブル学習を学びます。少しだけ機械学習の応用に近くなります。基礎的な機械学習を知ったうえで、より高度なアルゴリズムを学びます。これより前の章の知識が前提として記載されているので、学びやすい内容です。
最近の機械学習の潮流にも近いアルゴリズムなので、理解しておくことが重要です。
第10章 回帰分析―連続値をとる目的変数の予測
回帰分析を学びます。連続値の予測は実業務でもよく使われる予測です。基礎的な内容になりますが、連続値の予測における精度の評価など基本部分を学ぶことが重要です。
【より実践に近い経験を積もう!】コンペに参加してみる

機械学習になれたら、より実践に近い経験を積むためにコンペに参加してみましょう。
コンペとは世界中のデータサイエンティストが機械学習を競う選手権のようなものです。参加は無料で、自身のスキルアップのために活用できるため多くのデータサイエンティストがチャレンジしています。
オススメのコンペは下記の二つです。
英語に抵抗がない方は「Kaggle」で進めるのがよいでしょう。データ分析だけで手いっぱいなのに英語なんてやだ!という方は「SIGNATE」をオススメします。
書籍で学んだ知識だけでは結果はボロボロになるでしょう。大事なのは参加して結果を残すことです。まずは結果を残すことをゴールに参加してみましょう。
機械学習は様々な状況を経験して、スキルアップしていくことが大事です。行動あるのみです。
まずはやってみることが大事だよ。結果は後からついてくるからまずは行動してみて、後から考えるのが重要なポイントだよ。
【まとめ】機械学習を学んだらデータサイエンティストになろう!
機械学習の基礎を一通り学べれば、データサイエンティストの仲間入りです。ここまで学べたらデータサイエンティストの基礎スキルは身に付いています。
もし、20代でポテンシャルがある方であれば、データサイエンティストに”なる”ことをオススメします。データサイエンティストは未経験でも超オススメの職業です。詳細は下記をご覧ください。
データサイエンティストでスマートなキャリアを形成しましょう!
以下、本記事のまとめです。
- データサイエンティストにとって機械学習は重要?
→超重要!「専門性」を発揮するための必須スキル! - 機械学習ってどうやって実装するの?
→「Python」のライブラリを使えばOK!便利なライブラリが豊富! - 機械学習ってどうやって学ぶの?
→理論を理解する!実装してみる!条件を変えて遊んでみる!の3STEP! - 機械学習を一通り学び終えたらなにをすればいい?
→コンペに参加してみよう!より実践的な経験をしてスキルアップ! - データサイエンティストになろう!スマートなキャリアを作るために行動しよう!
今回は以上になります。













