

【自己紹介】
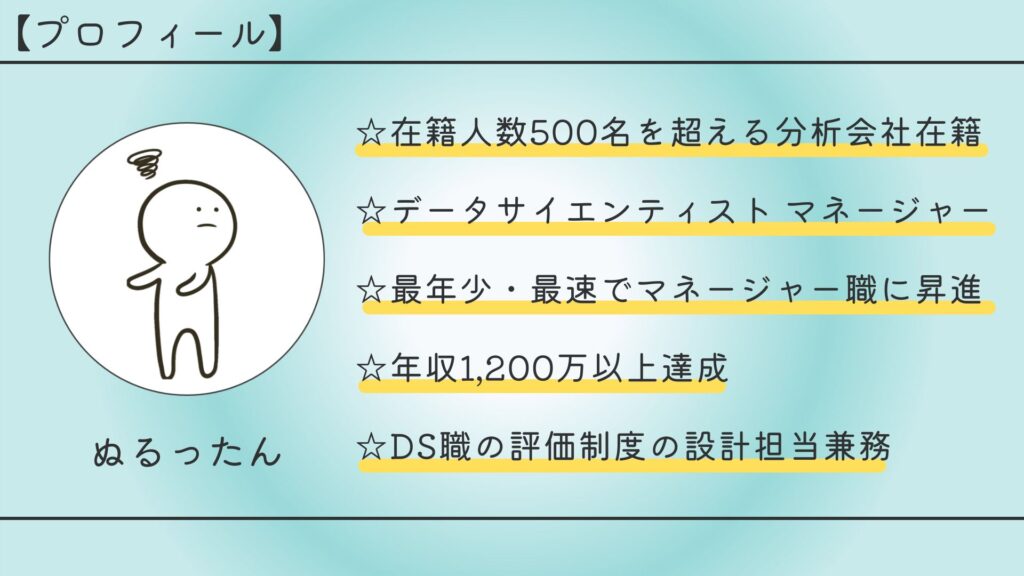
#Twitter:@Nurruttan / #YouTube:@Nurruttan
【転職支援サービス】

転職を検討しているデータサイエンティスト向けに【完全無料の】転職支援サービスを実施しています!
詳しくは下記をご覧ください!

【キャリア相談サービス】

キャリアに悩むデータサイエンティスト向けにキャリア相談サービスをやっています!
詳しくは下記をご覧ください!

- Chat-GPTってどうやって使えばいいの?
- データサイエンティストにオススメの使い方ってある?
- Chat-GPTを使うとなにがうれしいの?
「Chat-GPTって騒がれているけど、実際あんまり自分の作業に活用できてない」と思っているデータサイエンティストの方々向けにChat-GPTの使い方をオススメします。
Chat-GPTに雑多な作業は全部任せて、データサイエンティストは設計役として立ち回ることが最も有用な使い方です。
私は現在データサイエンティストとして働いており、実際本業でも「生成系AI」の活用を検討しています。そんな現役データサイエンティストの筆者が「Chat-GPT」のオススメの使い方を解説します。
この記事ではデータサイエンティストの有用な「Chat-GPT」の使い方を解説していきます。この記事を読むとデータサイエンティストの方の作業の生産性が大きく向上させることができます。
本記事の結論はこちらです。
- データサイエンティストはどうやってChat-GPTを使えばいい?
→コーディングを任せる!データサイエンティストは設計に力を使おう! - Chat-GPTを使うのに何が大事?
→重要な観点を正確に指示すること! - Chat-GPTで生産性を爆上げしよう!
では本題に移ります。
「Chat-GPT」は”超高性能”対話生成モデル

Chat-GPTは、自然言語処理技術を使った会話型AI(人工知能)の一種です。自然言語処理とは、人間が日常的に使っている自然言語をコンピュータが処理し、意味を理解して応答を返す技術のことを言います。
Chat-GPTは、OpenAIが開発したAI技術で、GPT(Generative Pre-trained Transformer)と呼ばれる深層学習モデルをベースにしています。GPTは、大量のテキストデータを学習し、それを基に自然言語での応答を生成することができる技術です。Chat-GPTはこのGPTをさらに改良して、より高度な応答生成技術を実現しています。
また、Chat-GPTは、多様なタスクに応用することができます。例えば、自動翻訳、質問応答、文章生成、要約、感情分析など、様々な分野で応用されています。
Chat-GPTは、自然言語処理技術の進歩によって、今後ますます高度な応答生成技術を実現することが期待されています。

Chat-GPTは世界中の言語を学習した対話生成モデルだよ。裏側には大規模なデータを学習させた「GPT」が使われているよ。色んな領域の活用が期待されているね。
「Chat-GPT」は様々なタスクをこなせる優秀なAI

Chat-GPTは、自然言語処理のさまざまな応用に活用されています。以下にChat-GPTができることについて詳しく説明します。
- 対話:Chat-GPTは、ユーザーとの対話を通じて、質問に答えたり、会話を続けたりすることができます。Chat-GPTは、前回の会話のコンテキストを覚えているため、自然な会話を継続することができます。
- 翻訳:Chat-GPTは、複数の言語間での翻訳を行うことができます。Chat-GPTは、入力されたテキストを解釈し、適切な言語に翻訳することができます。
- 要約:Chat-GPTは、大量のテキストデータを要約し、主要なポイントを抽出することができます。Chat-GPTは、入力されたテキストの内容を理解し、最も重要な情報を要約して提供することができます。
- 自然言語生成:Chat-GPTは、文章を自然な形で生成することができます。Chat-GPTは、特定のトピックに関する文章を生成することができます。
- 文書生成:Chat-GPTは、あるテーマに関する文章を生成することができます。Chat-GPTは、特定のトピックに関する情報を収集し、それに基づいて文章を生成することができます。
- 問答システム:Chat-GPTは、自然言語での質問に対して、正確な答えを提供することができます。Chat-GPTは、入力された質問に対して、最適な答えを生成することができます。
以上が、Chat-GPTができることの一部です。Chat-GPTは、自然言語処理の分野で幅広く活用されており、今後も新しい応用が増えていくことが期待されています。
「Chat-GPT」は会話できるだけでなくて、タスクをこなせる点が革命的だよ。それもかなりの高精度であるから世界を驚かせたんだよ。
データサイエンティストが「Chat-GPT」を上手に活用するポイント

データサイエンティストが「Chat-GPT」を上手に活用するには下記の2つの点が重要です。
- コーディング作業をChat-GPTに投げる
- データサイエンティストは設計に力を使うべし
コーディング作業をChat-GPTに投げる
Chat-GPTはコーディング作業もある程度できます。雑多なコーディング作業をChat-GPTに投げてしまうことでデータサイエンティストの作業効率を各段に上げることができます。
ざっくりテキストで指示するとある程度のプログラムを作ってくれる、優秀な部下がいるような感覚で作業を投げてしまいましょう。
データサイエンティストは設計に力を使うべし
コーディング作業は比較的時間がかかる作業です。その作業を一部Chat-GPTで代替可能なのであれば、データサイエンティストは設計部分に力を割くことができるようになります。
重要なポイントは観点を抑えて指示することです。具体的にやってほしいことを言語化して、Chat-GPTに投げることが重要です。
これはデータサイエンスを深く知っている人間にしかできない行為であり、モデル構築したことがない人間にはできないことです。
【実践】データサイエンティストの具体的な「Chat-GPT」活用方法

具体的な活用方法として、モデル作成を例にして「Chat-GPT」にコーディング作業を投げてみます。
モデル作成のプログラムを作成してもらう
まずはなにも考えずにモデル作成のプログラムを作ってもらいます。
(入力内容)
データの読み込みからモデル評価までを行うプログラムをPythonで書いてほしい、モデルはLightGBMを使いたい—(以下、Chat-GPTの回答)—
はい、おっしゃる通り、Pythonを使ってデータの読み込みからLightGBMを使ったモデル評価までを行うプログラムを書くことができます。以下に、一般的なプログラムの例を示します。
# 必要なライブラリをインポートする
import numpy as np
import pandas as pd
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# データを読み込む
data = pd.read_csv('data.csv')
# 特徴量とターゲット変数を分割する
X = data.drop(['target'], axis=1)
y = data['target']
# 訓練データとテストデータに分割する
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# LightGBM用のデータセットに変換する
train_data = lgb.Dataset(X_train, label=y_train)
test_data = lgb.Dataset(X_test, label=y_test)
# ハイパーパラメータを設定する
params = {
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': 'rmse',
'num_leaves': 31,
'learning_rate': 0.05
}
# モデルを訓練する
model = lgb.train(params, train_data, valid_sets=test_data, num_boost_round=100, early_stopping_rounds=10)
# テストデータを使ってモデルを評価する
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print('RMSE:', np.sqrt(mse))
上記のプログラムでは、まず必要なライブラリをインポートし、次にデータを読み込みます。データを読み込んだら、特徴量とターゲット変数を分割して、訓練データとテストデータに分割します。その後、LightGBM用のデータセットに変換し、ハイパーパラメータを設定します。最後に、訓練データを使ってモデルを訓練し、テストデータを使ってモデルを評価します。
上記のプログラムは一例であり、あなたが持つデータや問題に合わせて変更する必要があるかもしれません。また、ハイパーパラメータの設定やモデルのアーキテクチャは、最適な結果を得るために調整する必要があります。
—(Chat-GPTの回答(終))—
2行の文書だけでベースとなるプログラムを作ってくれるよ。人間がやると10分ぐらいかかりそうだよね。「Chat-GPT」なら30秒ぐらいで作ってくれるよ。
評価のプログラムを拡充してもらう
次に、評価のプログラムを拡充してもらうように指示をします。
(入力内容)
評価の部分にAUC曲線の表示を追加してほしい。あと、変数需要度を表示するプログラムも追加したい。—(以下、Chat-GPTの回答)—
# 必要なライブラリをインポートする
import numpy as np
import pandas as pd
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, roc_auc_score
# データを読み込む
data = pd.read_csv('data.csv')
# 特徴量とターゲット変数を分割する
X = data.drop(['target'], axis=1)
y = data['target']
# 訓練データとテストデータに分割する
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# LightGBM用のデータセットに変換する
train_data = lgb.Dataset(X_train, label=y_train)
test_data = lgb.Dataset(X_test, label=y_test)
# ハイパーパラメータを設定する
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'num_leaves': 31,
'learning_rate': 0.05
}
# モデルを訓練する
model = lgb.train(params, train_data, valid_sets=test_data, num_boost_round=100, early_stopping_rounds=10)
# テストデータを使ってモデルを評価する
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print('RMSE:', np.sqrt(mse))
# AUC曲線を表示する
auc = roc_auc_score(y_test, y_pred)
print('AUC:', auc)
# 変数重要度を表示する
feature_importance = pd.DataFrame({'feature': model.feature_name(), 'importance': model.feature_importance()})
feature_importance = feature_importance.sort_values(by='importance', ascending=False)
print(feature_importance)
上記のプログラムでは、まず必要なライブラリをインポートし、次にデータを読み込みます。データを読み込んだら、特徴量とターゲット変数を分割して、訓練データとテストデータに分割します。その後、LightGBM用のデータセットに変換し、ハイパーパラメータを設定します。最後に、訓練データを使ってモデルを訓練し、テストデータを使ってモデルを評価します。
上記のプログラムでは、モデルの評価部分にAUC曲線を表示するようにしました。また、モデルの評価後に、変数重要度を表示するようにしています。
—(Chat-GPTの回答(終))—
指示通りに追加機能を実装してくれたね。どうやるんだっけ?とかいつもなる処理があるよね。そんな時間も「Chat-GPT」に頼めば、解消されるよ。
パラメータのチューニングを自動化してもらう
次に、パラメータのチューニングを自動化してもらうように指示します。
(入力内容)
ハイパーパラメータのチューニングをoptunaで自動的にチューニングできるようにしたい。—(以下、Chat-GPTの回答)—
了解しました。以下に、optunaを使ってLightGBMのハイパーパラメータを自動的にチューニングするプログラム例を示します。
# 必要なライブラリをインポートする
import numpy as np
import pandas as pd
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, roc_auc_score
import optuna
# データを読み込む
data = pd.read_csv('data.csv')
# 特徴量とターゲット変数を分割する
X = data.drop(['target'], axis=1)
y = data['target']
# 訓練データとテストデータに分割する
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# LightGBM用のデータセットに変換する
train_data = lgb.Dataset(X_train, label=y_train)
test_data = lgb.Dataset(X_test, label=y_test)
# ハイパーパラメータをチューニングする
def objective(trial):
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'num_leaves': trial.suggest_int('num_leaves', 2, 31),
'learning_rate': trial.suggest_uniform('learning_rate', 0.01, 0.1),
'min_child_samples': trial.suggest_int('min_child_samples', 1, 20),
'subsample': trial.suggest_uniform('subsample', 0.1, 1),
'colsample_bytree': trial.suggest_uniform('colsample_bytree', 0.1, 1),
'reg_alpha': trial.suggest_uniform('reg_alpha', 0, 1),
'reg_lambda': trial.suggest_uniform('reg_lambda', 0, 1),
'max_depth': trial.suggest_int('max_depth', 3, 10),
'random_state': 42
}
# モデルを訓練する
model = lgb.train(params, train_data, valid_sets=test_data, num_boost_round=100, early_stopping_rounds=10, verbose_eval=False)
y_pred = model.predict(X_test)
auc = roc_auc_score(y_test, y_pred)
return auc
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=100)
# 最適なハイパーパラメータを取得する
best_params = study.best_params
print('Best Params:', best_params)
# テストデータを使ってモデルを評価する
model = lgb.train(best_params, train_data, valid_sets=test_data, num_boost_round=100, early_stopping_rounds=10, verbose_eval=False)
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print('RMSE:', np.sqrt(mse))
# AUC曲線を表示する
auc = roc_auc_score(y_test, y_pred)
print('AUC:', auc)
# 変数重要度を表示する
feature_importance = pd.DataFrame({'feature': model.feature_name(), 'importance': model.feature
—(Chat-GPTの回答(終))—(少し、文字数制限で切れてしまっています。)
指定されたパッケージを使って、チューニング部分を追加してくれたよ。本当に優秀な部下がいるみたいだね。これも30秒ほどで返ってくるから驚きだよね。
使いやすいようにモジュール化してもらう
最後に使いやすいようにI/O周りの整備およびモジュール化を指示します。
(入力内容)
アウトプットファイルを吐き出すプログラムも書いてほしい。あと、インプット・アウトプットファイルのパスを指定できるように切り出してほしい。最後に再利用性が高くなるように細かく関数化してもらってもいい?—(以下、Chat-GPTの回答)—
了解しました。以下に、指定したパスのインプットファイルからデータを読み込み、指定したパスのアウトプットファイルにモデルの評価結果や変数重要度を出力するプログラム例を示します。また、関数化し、再利用性を高めました。
import numpy as np
import pandas as pd
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, roc_auc_score
import optuna
# データの読み込み
def load_data(input_path):
data = pd.read_csv(input_path)
X = data.drop(['target'], axis=1)
y = data['target']
return X, y
# LightGBM用のデータセットに変換する
def convert_to_dataset(X_train, X_test, y_train, y_test):
train_data = lgb.Dataset(X_train, label=y_train)
test_data = lgb.Dataset(X_test, label=y_test)
return train_data, test_data
# ハイパーパラメータをチューニングする
def objective(trial, train_data, test_data):
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'num_leaves': trial.suggest_int('num_leaves', 2, 31),
'learning_rate': trial.suggest_uniform('learning_rate', 0.01, 0.1),
'min_child_samples': trial.suggest_int('min_child_samples', 1, 20),
'subsample': trial.suggest_uniform('subsample', 0.1, 1),
'colsample_bytree': trial.suggest_uniform('colsample_bytree', 0.1, 1),
'reg_alpha': trial.suggest_uniform('reg_alpha', 0, 1),
'reg_lambda': trial.suggest_uniform('reg_lambda', 0, 1),
'max_depth': trial.suggest_int('max_depth', 3, 10),
'random_state': 42
}
# モデルを訓練する
model = lgb.train(params, train_data, valid_sets=test_data, num_boost_round=100, early_stopping_rounds=10, verbose_eval=False)
y_pred = model.predict(X_test)
auc = roc_auc_score(y_test, y_pred)
return auc
# モデルを評価する
def evaluate_model(model, X_test, y_test):
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
auc = roc_auc_score(y_test, y_pred)
feature_importance = pd.DataFrame({'feature': model.feature_name(), 'importance': model.feature_importance()})
return np.sqrt(mse), auc, feature_importance
# モデルを作成する
def create_model(X_train, X_test, y_train, y_test):
train_data, test_data = convert_to_dataset(X_train, X_test, y_train, y_test)
study = optuna.create_study(direction='maximize')
study.optimize(lambda trial: objective(trial, train_data, test_data), n_trials=100)
best_params = study.best_params
model = lgb.train(best_params, train_data, valid_sets=test_data
—(Chat-GPTの回答(終))—(こちらもやや文字数制限で切れてしまっています。)
モジュール化までスラスラやってくれるよ。再利用性高くまとめてもらうことまで「Chat-GPT」にお願いができちゃうんだ。全部自分でやろうとすると最低30分ぐらいはかかりそうだよね。
「Chat-GPT」に単純なコーディングを任せてしまおう

「Chat-GPT」に単純なコーディングは任せてしまいましょう。
上記のように、「Chat-GPT」は単純なコーディングならできてしまいます。さらに再利用性をあげることまで丁寧に指示をすればやってくれます。
そのため、データサイエンティストが比較的時間を要するコーディング作業の一部は「Chat-GPT」に任せることができます。
観点を抑えて重要なポイントを指示することで、データサイエンティストの生産性を大きく向上させることができます。
【注意!】情報漏洩がないように気を付けよう

「Chat-GPT」は世界中で情報漏洩のリスクがあると懸念されており、業務での活用を禁じている企業も少なくありません。
特にデータサイエンティストたるもの、センシティブなデータを扱う場面もあるでしょう。
情報漏洩のリスクがある場合は絶対に「Chat-GPT」は利用しないでください。
【まとめ】Chat-GPTを上手に使って生産性を爆上げしよう!
データサイエンティストは「Chat-GPT」を上手に使って生産性を爆上げできます。使わない手はないです。雑多なコーディング作業を「Chat-GPT」に投げて、価値高い仕事に力を使いましょう!
以下、本記事のまとめです。
- データサイエンティストはどうやってChat-GPTを使えばいい?
→コーディングを任せる!データサイエンティストは設計に力を使おう! - Chat-GPTを使うのに何が大事?
→重要な観点を正確に指示すること! - Chat-GPTで生産性を爆上げしよう!
今回は以上になります。














