

【自己紹介】
#Twitter:@Nurruttan / #YouTube:@Nurruttan
【転職支援サービス】

転職を検討しているデータサイエンティスト向けに【完全無料の】転職支援サービスを実施しています!
詳しくは下記をご覧ください!

【キャリア相談サービス】

キャリアに悩むデータサイエンティスト向けにキャリア相談サービスをやっています!
詳しくは下記をご覧ください!

- 未経験からデータ分析の学び方が知りたい
- Pythonでどうやってデータ分析をするのか知りたい
- 「Pythonによるデータ分析入門」ってめっちゃ分厚い?全部読まないとダメ・・?
未経験でデータ分析ってどうやって学べばいい?Pythonで実際にどうやってデータ分析するの?など悩んでいる人もいるのではないでしょうか?
今回はPythonでデータ分析を学ぶためにオススメの「Pythonによるデータ分析入門」を紹介します。さらに、どのように「Pythonによるデータ分析入門」を使って学習すべきかまで詳細に解説します。
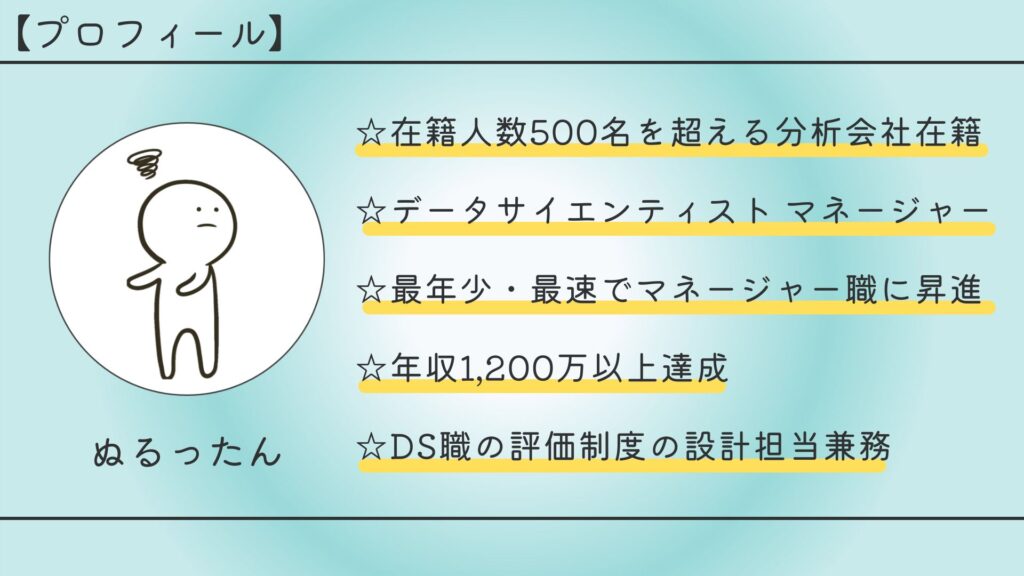
筆者は約500名が在籍する会社で長らくデータサイエンティストとして働いています。いまではデータサイエンティストとして活躍できているものの、スタートは未経験からの転職でした。
実際に筆者が学んだ方法を基に「Pythonによるデータ分析入門」を使った「Pythonでのデータ分析」の学習方法を解説します。
この記事を読むと、Pythonでデータ分析する方法がわかります。さらにこの記事を実践するとデータ分析の基礎が身に付き、データサイエンスを学ぶためのスタートに立つことができます。
本記事の結論は下記になります。
- データ分析に必要なプログラミング言語は?
→「Python」一択!データ分析に必要な機能が満載! - 「Pythonによるデータ分析入門」ってなにを学べる?
→Pythonで「データ分析」するための代表的な処理をほとんど学べる! - データ加工を学んだらなにを学ぶべき?
→いよいよ機械学習を学ぼう!データサイエンスを学習! - データ加工はコスパよく学ぼう!一通り学べば次のSTEPへ!いざ、機械学習!
では、本編にいきます。
データ分析に必要なプログラミング言語は「Python」

データ分析に必要なプログラミング言語は「Python」です。なぜなら、Pythonはデータ分析を効率的に実施できる豊富なライブラリがあるからです。
ライブラリとは、ある程度まとまった汎用性の高い処理(関数・クラス・その他)を他のプログラムから読み込むことで、使うことが出来るようにしたファイルです。
AI Academy Media:【初心者向け】モジュール・パッケージとは何か?
これらのライブラリを使用することで、データの読み込み、前処理、可視化、モデリングなど、データ分析に必要な機能を簡単かつ効率的に実行することができます。
また、Pythonは多くのデータ分析コミュニティで広く使われており、問題解決のための情報やサポートが豊富にあります。これらの要素が組み合わさって、Pythonはデータ分析に適した言語となっています。
そのため、データ分析を行うためには、Pythonの学習が必須です。Pythonを使いこなせば、データ分析のスキルを高めることができます。
Pythonがなにかわからない!という方は下記をご覧ください。
⇒【未経験から】Pythonの基礎を学ぶオススメ書籍!「入門Python 3」の使い方 はコチラ

他にも「SQL」や「R」など聞くと思うけど、最先端のデータ分析をやるなら「Python」一択だよ。いまどき「SQL」や「R」だけで分析している企業は将来性がないから入る必要がないよ。「Pyrhon」をまずは学ぶことが最善だよ。
【重要】書籍で学ぶ際に重要なポイント

書籍でプログラミングを学ぶSTEP
書籍でプログラミングを学ぶSTEPは下記のようになります。
- ページを読み進める
- 書いてある実行プログラムを写経(書き写す)してみる
- 実行する
- 成功をよろこぶ
プログラミング初心者は簡単な成功体験を積むのが重要です。こんな僕にもプログラミングができた!と感じてほしいです。
そのため、まずは記載されているプログラムを書き写して実行することから始めましょう。そして、なにより成功をよろこびましょう。重要なのは実行してよろこびを感じることです。
他にも「SQL」や「R」など聞くと思うけど、最先端のデータ分析をやるなら「Python」一択だよ。いまどき「SQL」や「R」だけで分析している企業は将来性がないから入る必要がないよ。「Pyrhon」をまずは学ぶことが最善だよ。
書籍でプログラミングを学ぶ重要な心構え
書籍でプログラミングを学ぶ重要な心構えは下記です。
- 1時間以上考えて理解できなければ諦める
1時間以上考えて理解できなければあきらめましょう。大丈夫です。
完全に理解しようとしないでください。
ここでは理解しきれずとも、将来的にその要素の存在を思い出せれば大丈夫です。使わなければいけない時に思い出せれば十分です。重要なことはすべてを網羅的に知ることです。
わからないことに時間を使い過ぎてもダメだよ。1時間ほど考えてもわからなかったら飛ばして、次に進もうね。使うときに改めて使えれば問題ないよ。
「Pythonによるデータ分析入門」の使い方
「Pythonによるデータ分析入門」はすべて学ぶ必要はありません。コスパのよい部分を集中的に学びましょう。
「Pythonによるデータ分析入門」で学ぶべき章は下記になります。
- 4章:Numpy
- 5章:Pandas
- 7章:データクリーニングと前処理
- 9章:プロットと可視化
詳しく解説していきます。
4章:Numpy
Numpyの使い方について学びます。
Pyhtonの「list」に近しい考え方なので、一度Pyhtonを学習した方にとってはあまり難しくはないでしょう。
Numpyは基礎的な演算によく利用するライブラリです。基礎の基礎として位置づけられます。複雑ではないので、どのようなものかしっかり学び名生。
行列の演算になれることができれば及第点です。
Numpyは行列演算に特化したライブラリだよ。超基礎的な演算に便利だからしっかり使えるようにしておこうね。
5章:Pandas
Pandasの使い方について学びます。
Pandasは機械学習の入力直前、出力直後に使う重要なライブラリです。機械学習などを高度な分析を実施する際にPandasは欠かせません。
重要なのは「どのような処理ができるか?」を理解することです。細かいコーデディングの仕様などはどうせ忘れます。後で調べて実装できれば問題ないです。
Pandasはこれから一番使っていくライブラリと言っても過言ではないよ。使い方とできることを覚えようね。細かいコーディングは調べて実装できれば問題ないよ。
7章:データクリーニングと前処理
データ加工の考え方を学びます。
「汚いデータってなに?どんなデータが入っていると困るの?」という素朴な疑問を理解します。データ分析をする際に理解しておかなけばいけない観点を学びましょう。
この章でデータ加工の重要性をリアルに実感することができます。
データクリーニングと前処理はデータ分析に重要なプロセスだよ。汚いデータ、綺麗なデータがどのようなものかをしっかり理解して、データ分析に適切な形でデータを加工できるようになろうね。
9章:プロットと可視化
データの可視化を学びます。
加工したデータ・分析結果を可視化する方法・パターンを理解します。ここでも「どのような可視化ができるか?」を理解することが重要です。
データの可視化一つで分析結果の持つ意味合いは大きく変わります。どのようなデータの可視化ができるか学びましょう。
繰り返しになりますが、細かいコーディングの仕様は忘れます。後から調べればいいです。しかし、何ができるか知らなければ調べることすらできないので、何ができるかを学びましょう。
データをどのように可視化するかは分析結果を見せるときに重要だよ。Pythonでどのような可視化ができるかしっかり学ぶことで適切な可視化ができるようになるよ。
「Pythonでのデータ分析」を学んだら「機械学習の実装」へ

「Pythonでのデータ分析」を学んだら「機械学習の実装」へ移りましょう。データ加工でできることは学べたので、次の書籍に進んでより実践的な内容を学んでいきましょう。
私のオススメはこちら。
- サンプルプログラムが豊富にあること!
- 実装だけでなく理論をほどよく解説してくれていること!
- なにより機械学習が学べること!
まず、サンプルプログラムが豊富で写経しやすいです。これは初心者の学習にとても重要です。
次に、実装だけでなく理論の解説があることです。機械学習のアルゴリズムを理解しながら学習することができます。そして、これが初心者にとってほどよく書かれています。
最後に、機械学習が学べることです。自分の手で機械学習が動かせている実感を持てるため、満足感が得られます。
詳しくは下記をご覧ください。
⇒【未経験から】機械学習の実装を学ぶオススメ本を紹介!学び方まで徹底解説!
機械学習がどのようなものなのか、自分の手で動かせることはとてもうれしいよ。理論的なことも理解した上で、実装できてデータサイエンスが学べている実感があるよ。
【まとめ】データ加工はコスパよく学ぼう!定着はあとからでOK!
データ加工は、コスパよく学びましょう。
何度も言いますが、細かい仕様は忘れます。調べて実装できれば問題ありません。調べて、使っていく中で定着します。まずはエラーが出なければOK!という感覚でサクサク学んでいくことが重要です。
未経験からデータサイエンスを学ぶ方法は下記に詳しく解説していますので、ぜひご覧ください。

本記事のまとめです。
- データ分析に必要なプログラミング言語は?
→「Python」一択!データ分析に必要な機能が満載! - 「Pythonによるデータ分析入門」ってなにを学べる?
→Pythonで「データ分析」するための代表的な処理をほとんど学べる! - データ加工を学んだらなにを学ぶべき?
→いよいよ機械学習を学ぼう!データサイエンスを学習! - データ加工はコスパよく学ぼう!一通り学べば次のSTEPへ!いざ、機械学習!
今回は以上になります。














