

【自己紹介】
#Twitter:@Nurruttan / #YouTube:@Nurruttan
【転職支援サービス】

転職を検討しているデータサイエンティスト向けに【完全無料の】転職支援サービスを実施しています!
詳しくは下記をご覧ください!

【キャリア相談サービス】

キャリアに悩むデータサイエンティスト向けにキャリア相談サービスをやっています!
詳しくは下記をご覧ください!

こんにちは、ぬるったんです。
今回はRAGとはなにか?なぜ企業で必須なのか?というテーマで解説していきます。
昨今、生成AIが一つのビジネストレンドになっていますが、多くは個人で活用するAIツールの情報発信が多く、企業でどう活用するのか?という点で語られることが少ないように思えます。
しかし、データサイエンティストとしては生成AIを企業活用することが求められるので、企業でどのように生成AIを活躍していくのかは重要なテーマです。
その中でも、基礎に当たるRAG(Retrieval-Augmented Generation)について解説していきます。
YouTube版はこちらです。
RAGとはなにか?
そもそもRAGとはなにか?という点について解説していきます。
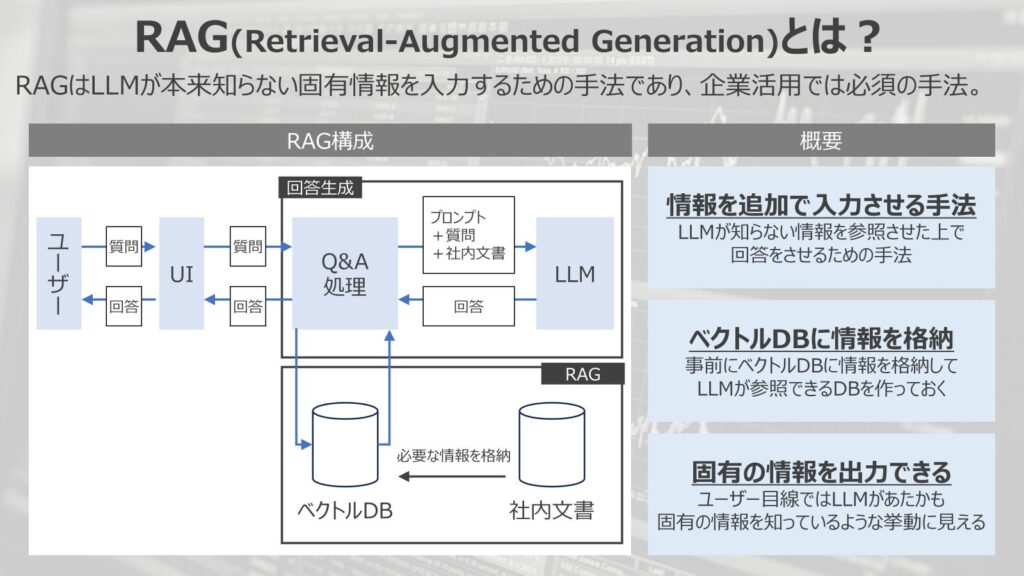
RAG(Retrieval-Augmented Generation)はLLMが本来知らない固有情報を入力するための手法であり、企業活用では必須の手法です。
左の図がRAGの一般的な構成です。
ポイントは主に3つです。
一つ目が、情報を追加で入力させる手法であるという点です。
LLMが知らない情報を参照させた上で回答をさせるための手法であり、LLMに新たに知識習得させることができます。
二つ目は、ベクトルデータベースに情報を格納するということです。
事前にベクトルデータベースに情報を格納してLLMが参照できるデータベースを事前に作っておくことが必要になります。
三つ目が、固有の情報を出力できるという点です。
ユーザー目線ではLLMがあたかも固有の情報を知っているような挙動に見えます。
実際は、情報を参照しているだけですが、ユーザー目線では固有の情報を知っているように見え、新たなユーザー体験を作ることができます。
RAGがなぜ必要なのか?
RAGがなぜ必要なのか?という点についてですが、結論から言うと、企業活用する上で、社内特有の情報を参照することが必須であるからです。
社内活用進めていく上では、RAGでの情報参照が重要な要素になります。
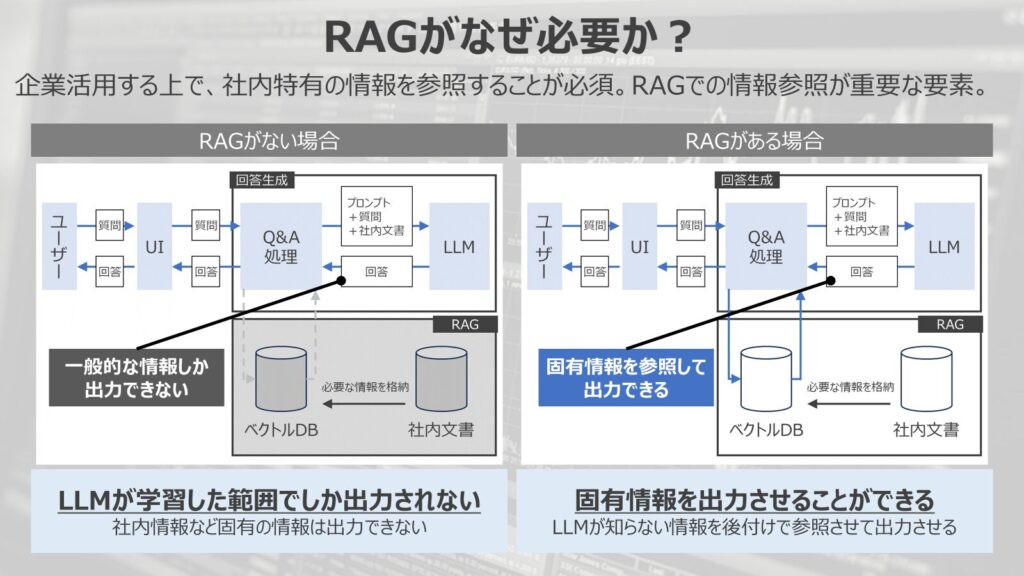
RAGがない場合
仮にRAGがなかった場合のことを考えてみましょう。
左図のように参照情報がなければ、LLMからは一般的な情報しか得られず、LLMが学習した範囲でしか出力されません。
社内情報など固有の情報は出力できず、企業内で活用するには、片手落ちです。
RAGを活用した場合
一方で、RAGを活用した場合は生成AIが事前に準備したベクトルデータベースを参照して回答を生成してくれます。
そのため、社内特有の固有情報を参照して出力することができます。
LLMが本来知らない情報を後付けで参照させて出力させることができるため、社内の情報を加味して回答が生成できるというのが、大きなメリットです。
このように、企業で生成AIを活用する時には、ほとんどの場合で固有の情報を参照して使いたくなるため、新たな情報参照を実施するために、RAGのスキルが重要になってきます。
Fine-Tuningとの違いは?
ここで新たな知識習得の手法にはファインチューニングという手法もあります。
このファインチューニングとの違いを解説していきます。
システム構成
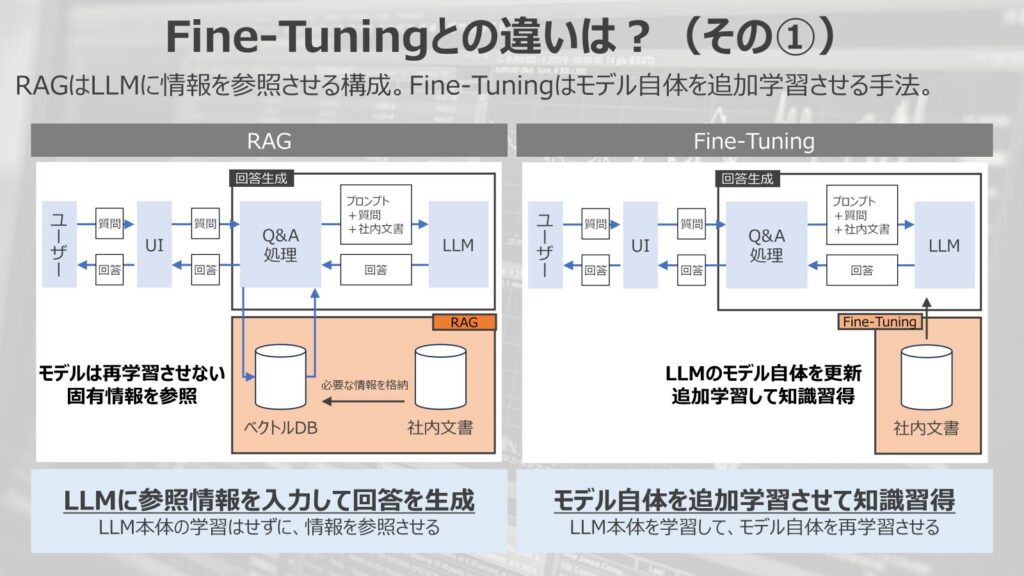
RAGは前述したように、LLMに情報を参照させる構成を取ります。一方、ファインチューニングはモデル自体を追加学習させる手法です。
左の図のように、RAGでは外付けで情報が入力されているような構成を取り、モデル自体を再学習することはありません。
あくまでLLMに対して、参照情報を紐づけるだけで、LLMが情報を参照して、回答を生成する構成です。
いわば、外付けハードディスクのような構成を取ります。
一方で、ファインチューニングはLLMのモデル自体を更新して、追加学習して知識習得をします。
モデル自体を直接的に更新しにいく手法であり、LLM本体を追加学習させます。
これは、例えると内部メモリを書き換えるようなアプローチで新たな知識を習得させるアプローチを取ります。
このように、RAGとファインチューニングは似て非なるものです。
知識習得という文脈では同じように映りますが、実際には全く異なるアプローチであり、それぞれメリット・デメリットがあります。
メリット・デメリット
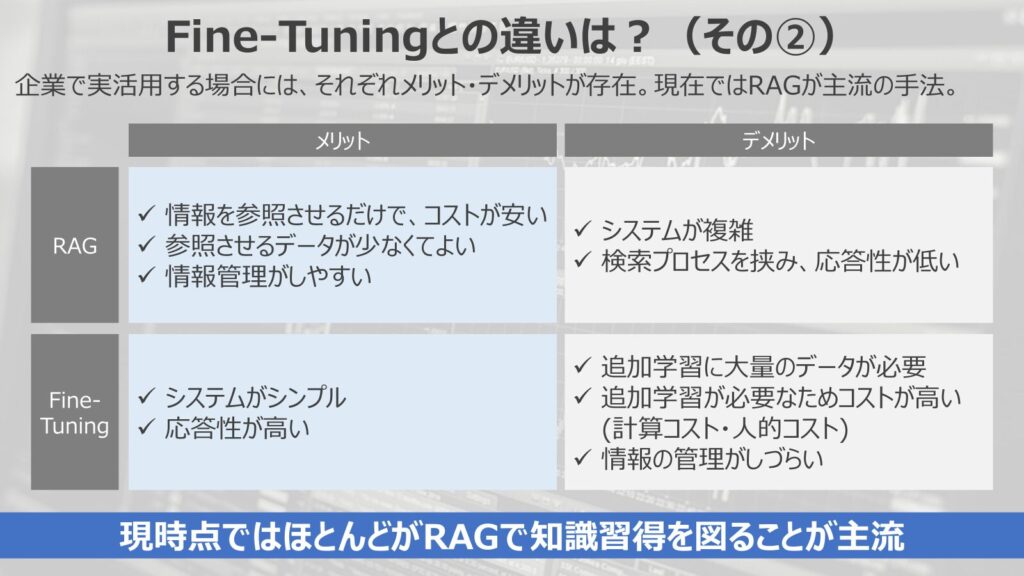
企業で実活用する場合には、それぞれメリット・デメリットが存在します。
RAGのメリットは、
- 情報を参照させるだけで、コストが安い
- 参照させるデータが少なくてよい
- 情報管理がしやすい
と、いう点です。準備するデータも少なく、情報を参照させるだけであることから、コストも低く実装できます。
また、参照情報が目に見える形でファイルとして管理できるので、情報管理がしやすく、情報統制が取りやすいというメリットがあります。
RAGのデメリットとしては、
- システムが複雑
- 検索プロセスを挟み、応答性が低い
という点が挙げられます。
外付けして、情報を参照させるため、システムがやや複雑化します。また、参照情報を検索するプロセスが走るため、応答性がやや低くなる点はデメリットと言えるでしょう。
一方で、ファインチューニングのメリットとして
- システムがシンプル
- 応答性が高い
という点が挙げられます。モデル自体を更新しているので、単にモデルに質問をすればいいだけです。
システムはシンプルであり、応答性が高いシステムを構築することができます。
ファインチューニングのデメリットとしてあるのが、
- 追加学習に大量のデータが必要
- 追加学習が必要なためコストが高い(計算コスト・人的コスト)
- 情報の管理がしづらい
と、いう点です。
昨今のLLMは100億を超えるパラメータを持ち、非常に大型の言語モデルです。
このような大型の大規模言語モデルに対して、追加学習を進めるには、大量のデータが必要であるだけでなく、計算リソースも莫大になります。
具体的に言うと、GPUが大量に必要のため、人的コストも計算コストも莫大になってしまいます。
また、学習に用いた大量のデータを管理しなければならないので、情報の管理がしづらいという点も実運用を鑑みると大きなデメリットになります。
と、いうところから、現時点ではほとんどがRAGで知識習得を図ることが主流となっています。
ファインチューニングが使われるシーンはあまりなく、RAGで実装することがほとんどであるというのが、いまの生成AIの企業活用の実態です。
まとめ
今回はRAGってそもそも何なのか?なぜ企業活用で必須なのか?という点について解説しました。
- RAGはLLMに固有の知識を習得させるための手法
- 企業で活用する場合は、社内情報を参照させたいため、RAGは必須となる
- 知識習得には”Fine-Tuning”の選択肢もあるが、RAGの有用性が高く、RAGでの実装がほとんど
と、いうのが今回のまとめになります。
生成AIのスキルは今後のデータサイエンティストのキャリア構築には非常に重要なスキルになってきます。
今後も生成AIの企業活用というテーマで発信していこうと思います。
今回は以上です。ありがとうございました。














