【自己紹介】
#Twitter:@Nurruttan / #YouTube:@Nurruttan
【転職支援サービス】

転職を検討しているデータサイエンティスト向けに【完全無料の】転職支援サービスを実施しています!
詳しくは下記をご覧ください!

【キャリア相談サービス】

キャリアに悩むデータサイエンティスト向けにキャリア相談サービスをやっています!
詳しくは下記をご覧ください!

こんにちは、ぬるったんです。
今回は、RAGにおけるデータクレンジングの重要性というテーマで解説していこうと思います。
昨今、話題となっている生成AI活用を進める上で欠かせないのがRAGです。RAGを上手く活用するためにはあらゆることを考えなければなりません。
その中でも今回はデータクレンジングの重要性について解説していこうと思います。
私自身も実務の中で生成AIの活用を進めている中での実体験も合わせて、解説していこうと思います。
どのようにRAGの精度を向上させるのか?
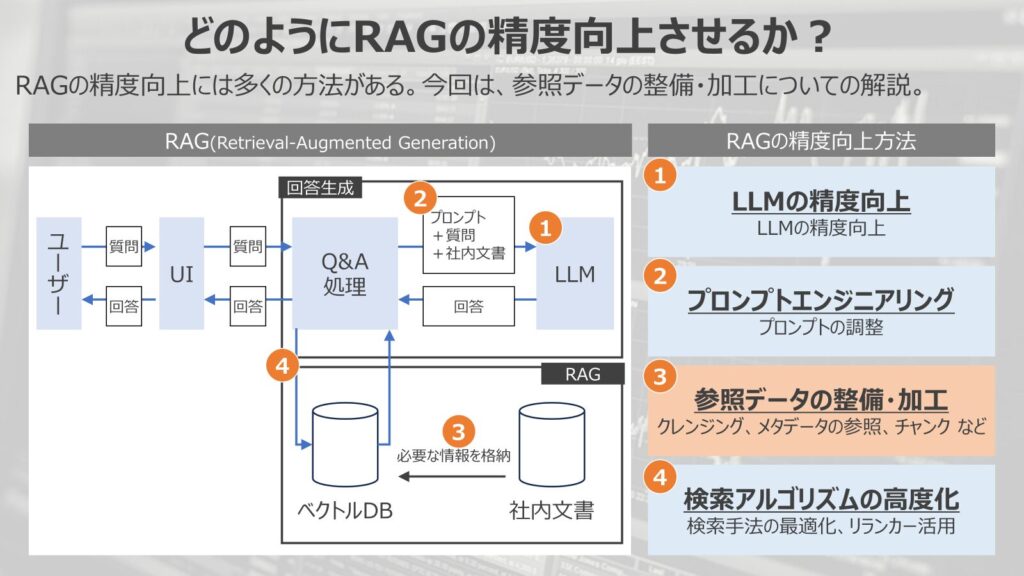
そもそもRAGの精度をどのように向上させるのか?という点を解説していきます。
図がRAGの構成になります。
RAGでは、事前にベクトルデータベースに社内情報などの固有情報を参照させて、ユーザーの検索に対して、固有情報を参照させて回答を生成する手法です。
このようなRAGの精度向上には大別して4つ方法が有効です。
- LLMの精度向上
LLM自体の精度を向上させて、RAGの性能を向上させる手法 - プロンプトエンジニアリング
LLMへの指示、プロンプトを調整して、RAGの性能を向上させる方法 - 参照データの整備・加工
参照させるデータのクレンジング、データの参照、チャンクのさせ方など参照データを綺麗にして、RAGの性能を向上させる方法 - 検索アルゴリズムの高度化
検索手法を最適化、リランカーの導入などにより、情報への検索性能を上げて、RAGの性能を向上させる方法
今回は、この4つの中で、3つ目の参照データの整備・加工に関して焦点を当てた内容になっています。
なぜ参照データの整備・加工が重要か?

ここから参照データの整備・加工がなぜ重要かという点について解説していきます。
企業には様々なデータ形式がある

まず、大前提として企業には様々なデータ形式で情報が保存されています。
皆さんも企業で働かれていることが大半だと思いますが、業務を進めていく上で用途によって様々なファイル形式でデータを管理していることが多いでしょう。
正式版として、pdfファイルで保存したり、なんらかのひな形はwordで格納したり、構造的に管理をしたい場合はExcelを使ったり、と業務に合わせて様々な形式でデータが保存されています。
また、全社員に展開するにはpdfファイルのみで元データは限られた管理者のみしか触れない、などといった情報統制の観点でも役割によってアクセスできるファイルが限られているという運用が多いはずです。
そのため、企業ではあるゆる形でデータが保存されているというのはどのような企業でも同様の大前提になります。
単純な機械処理だと欲しい情報を抽出できない

このようにあらゆるデータ形式で情報が保存されていることがRAG構築上では厄介な悩みになります。
ここではpdfを例に取って説明します。
pdfは人間にとっては扱いやすいファイルですが、機械目線だとやや扱いづらいファイル形式です。
簡略化して説明すると、すべての情報が画像として扱われ、文字情報なのかオブジェクト情報なのかの区別をつけることが難しいという側面があります。
このようなpdfファイルをから情報抽出するために、GPTを活用した画像認識を行い、情報抽出することが考えられるやり方ですが、実際にpdfファイルを読み込んだ際に上手く情報が抽出できない場合が多々あります。
例えば、図のように画像データを上手く認識できなかったり、二段構成のテキスト情報を字続きで読み込んでしまうといったこともたまに生じます。
また、今回の図には書かれていませんが、表形式のデータを上手く読み取って情報集約できなかったりと人間が目検で抽出してほしい情報を機械的に抽出しきれないといった課題が発生します。
特に、画像情報や表の情報はテキストとして情報集約させるのではなく、画像・表データとして保存しておきたいというニーズも多く発生します。
このようにファイル形式によっては単に情報抽出するだけでは、人間が欲しい情報を上手く抽出できない場合が起きてしまう場合があります。
人間が欲しい情報を適切に抽出すべき

本来的には人間が欲しい構造で情報を抽出すべきです。
pdfの中でも画像部分は画像データとして情報を保存して格納したり、画像のタイトルはテキストデータとして画像のメタデータとして保存したくなります。
テキスト部分は正確に意味の塊ごとに情報を集約させて情報を格納しておきたいというのが、本来やりたいことです。
このように各ファイルデータから必要なデータを任意の範囲で取得するためには、幾ばくかの工夫が必要であり、単にデータをたくさん食わせればRAGの精度が上げられるかというとそんな単純な話ではありません。
データサイエンティストであれば、肌感があると思いますが、機械学習モデルに対して、何も考えずに多くのデータを入れても精度は上がりません。
適切にデータの前処理を行い、正しく・綺麗なデータを与えることでモデルの精度を向上させることができます。
この構造がRAGでも同様に発生します。
だからこそ、データの前処理・クレンジングがRAGの精度向上に直結し、精度向上を実現する上で欠かせない検討事項になるということです。
どうデータを整備・加工するか?

ここから、実際にどうデータを整備・加工するか?という点について解説していきます。
結論から言うと、データ整備・加工はユースケースに応じて変える必要があります。
そのため、一概には言い切れない部分がありますが、ここでは代表的な下記の3つのポイントで説明していきます。
- メタデータの管理
- 非テキスト情報の意味抽出
- テキストのチャンキング
メタデータの管理

一つ目がメタデータの管理です。
そもそもファイルそのものの情報をメタデータとして抽出して、RAG検索時に活用するという使い方は有効な手法になります。
例えば、ファイルのジャンルであったり、データ格納日、格納者が誰なのか、どのくらいのページ数なのかなど、ファイルそのもののメタデータを上手く抽出して管理することが重要です。
例えば、最新の情報のみを検索したいというような場合であれば、データの格納日が直近のものに絞って検索して、RAGで回答生成するということが考えられます。
一般的に検索する情報が多ければ多いほど、検索性能は落ちます。
そのような場合でも、メタデータを適切に管理して、フィルタリングしてから検索することで検索負荷を低減させて、応答性やコストを削減することが出来ます。
このようにRAGを活用した情報検索ではファイルのメタデータの管理は重要な要素として位置付けられます。
非テキスト情報の意味抽出

二つ目が、非テキスト情報の意味抽出です。
図や表などの非テキスト情報を適切に意味抽出して管理することはRAGの精度を向上させるために重要なポイントの一つになります。
画像や表で表現されている意味情報を適切に抽出して、検索できるような形に落とし込むことが必要です。
特に、人間に対して、わかりやすく表現しようとすればするほど、画像や表データの割合は多くなっていきます。
テキストだけではわかりづらい構造やエビデンスを示すための表などは多くのドキュメントで登場する表現パターンになります。
そのため、画像や表では重要な情報が記載されていることも多く、必ず情報集約することが求められます。
また、画像・表データの抽出は場合によってはユーザーインターフェースの向上という観点でも大きく期待できる要素です。
ユーザーのクエリに対して、適切な情報をテキストで返すだけでなく、画像・表などとセットで返すことでユーザー目線で非常に使いやすいシステムを構築することができます。
このように、RAGの精度向上だけでなく、UI/UXという観点でも重要になってくるのが、非テキスト情報の意味抽出になります。
テキストのチャンキング

最後がテキストのチャンキングです。
チャンキングというのは、テキストデータを小分けすることを指します。RAGではテキストデータを小分けにして、データベースに格納します。
RAGを構築する際に必ず発生するのが、テキストをどのようにチャンクしてどうデータベースに格納するのか?という論点です。
テキストをどのような長さでチャンクするのか?それぞれのチャンクはオーバーラップさせてチャンクさせるべきか?などといった点は必ず検討すべき事項になります。
王道のやり方としては、セマンティックチャンキングと呼ばれる意味の区切りごとにチャンクを行い、データベースに格納するやり方が一般的です。
しかし、チャンクのさせ方はドキュメントやユースケースによるため、ベストプラクティスは試行錯誤的に決めていく必要があるという点は難しいポイントになります。
このように、テキストデータをいかにうまくデータベースに格納して、検索性をあげるかという点でも検討が必要となってくるため、テキストデータの整備もRAGの性能向上には重要なポイントです。
具体的なデータクレンジングのやり方は?
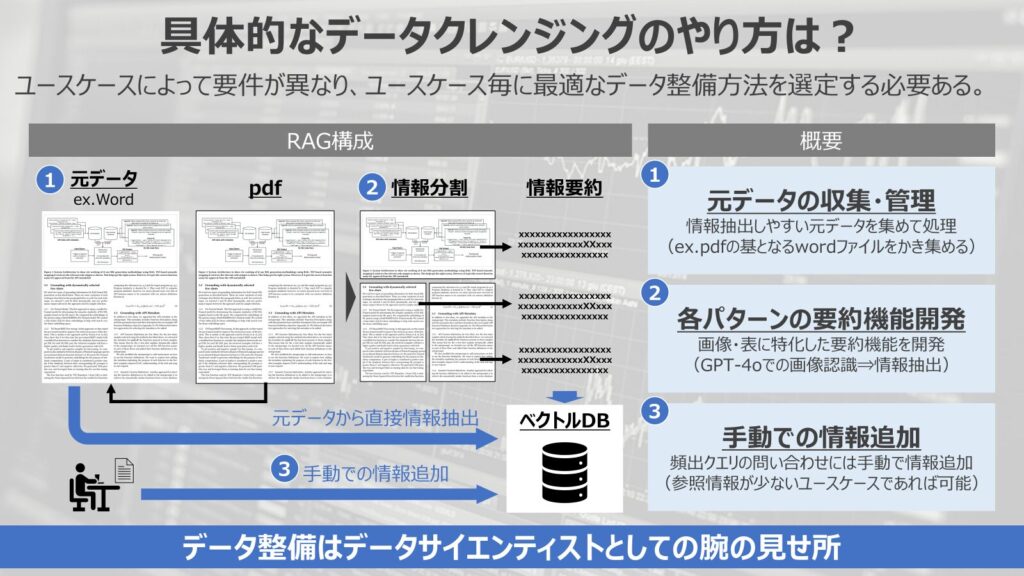
最後に、具体的にデータクレンジングはどうやるのか?という点について解説していきます。
今回は具体的な技術の解説ではなく、組織でRAGの精度向上を進める上で、俯瞰的な目線で解説していきます。
大きく3つのやり方を解説していきます。
- 元データの収集・管理
- 各パターンの要約機能開発
- 手動での情報追加
元データの収集・管理
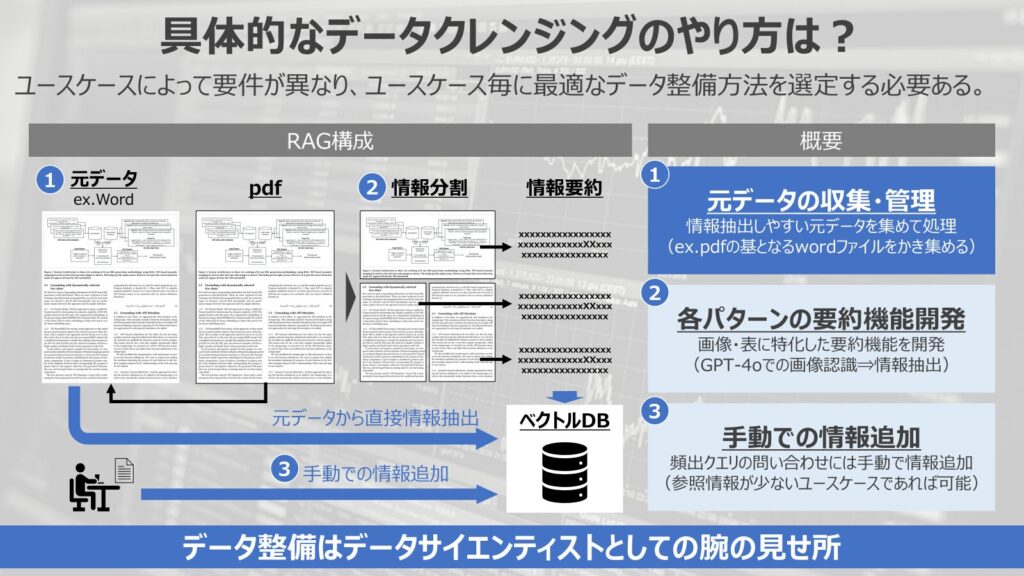
一つ目が元データの収集・管理です。
先の例で挙げたように、データクレンジングが必要な場合の多くが機械が認識しづらい形式でのデータであることが多いです。
上手く対応するためには、pdf前の元データを収集して、適切に管理することで任意の情報抽出がしやすくなります。
画像・表データの格納ルールを決めて、綺麗に情報を管理して情報集約を行う仕組みを作ることは一つの選択肢になります。
非常に泥臭い方法になりますが、データを正しく管理することで中期的にもRAGの精度向上を実現することができるため、重要な考え方になります。
RAGの精度向上のためには参照させるデータを綺麗にしておく必要があるので、データ管理にも口を出してデータ整備を図っていく必要があります。
各パターンの要約機能開発
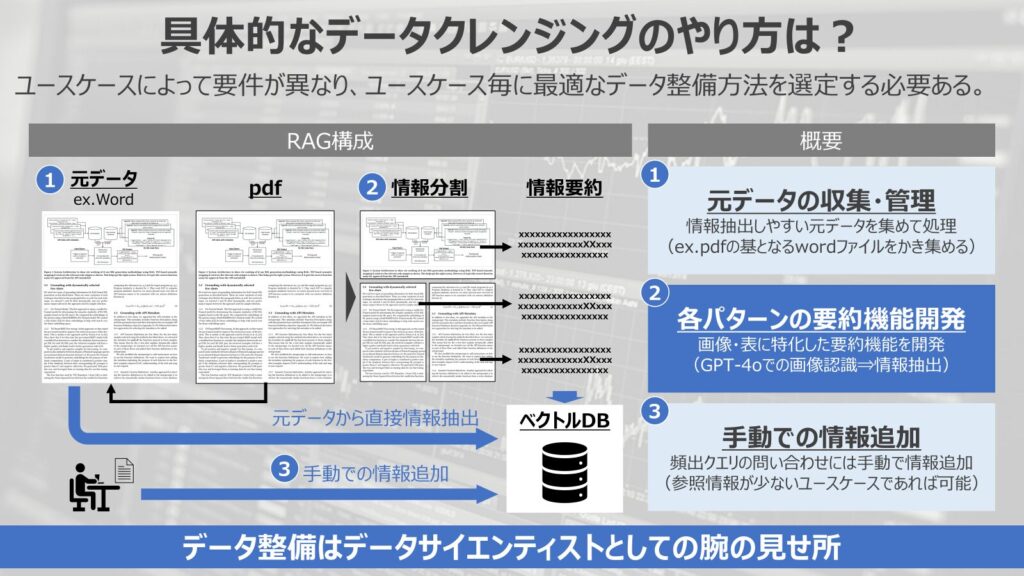
二つ目が各パラメータの要約機能の開発です。
画像データの情報抽出や表データの情報抽出を適切に行うための、機能開発を行うやり方です。
企業でRAGを構築際に扱うデータの多くはテキストデータと画像・表データが混在したドキュメントになることが多いでしょう。
まずは、そのデータから画像部分、表部分を上手く認識させて分割するというやり方を検討する必要があります。
場合によっては、資料の中に別の資料のリンクが埋め込まれていることもあり、各データの関係性を抽出する必要も考えられます。
このような場合では、ドキュメントから画像データや関連データを抽出して、整理する必要が出てきます。
データを整理した後に、各データを上手く情報集約させるステップが走ります。
画像データや表データはGPT-4oなどの画像認識を噛ませて、任意の情報を抽出するような処理を加えることが多いです。
情報集約のプロンプトは画像と表で同様のものを使って同じ情報を抽出するのか、異なるプロンプトを活用して、異なる情報を抽出するのかはRAGのユースケースによります。
それぞれのユースケースの要件によってやり方を変える必要がある点は、データサイエンティストとしての力量が試されるポイントになります。
手動での情報追加
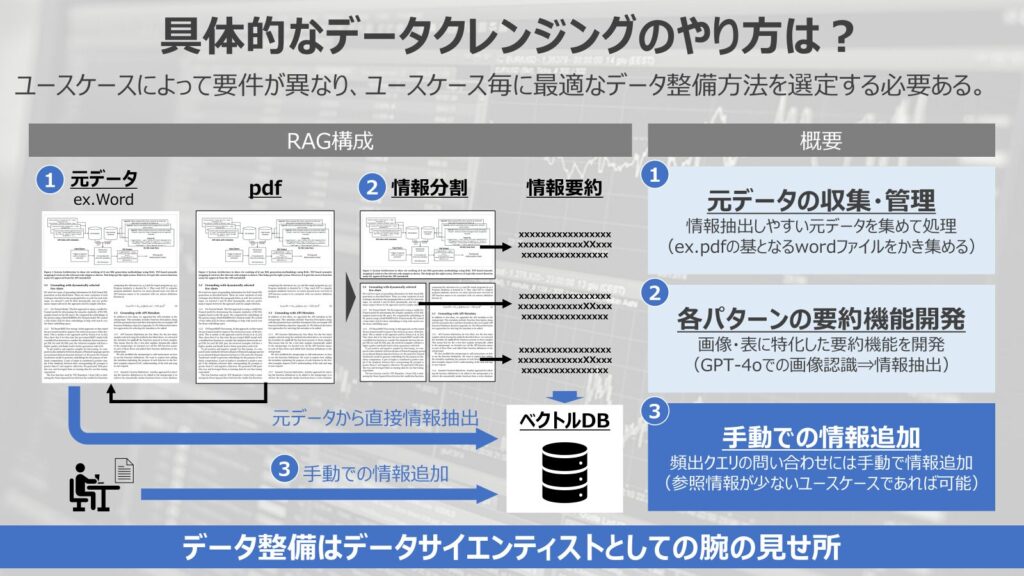
最後に、手動での情報追加というやり方もあります。
頻出する問い合わせに対して、手動で情報を追加するというやり方です。
そもそもRAGとして情報検索させたい場合に、参照するデータが足りていなければ、得たい回答が返ってくることはありません。
例えば、社内規定を読み込んだRAGを活用する際に、社内の申請方法を知りたいのに、申請の概要だけ出てきて、具体的な申請手順が出てこない、といったことが考えられます。
これは社内規定は読み込めているものの、具体的な申請手順が規定には記載されておらず、RAGがユーザーのクエリに対して適切に回答できていないということが原因です。
このような場合に対応するためには、そもそもデータを追加させる必要があります。
元データがあればいいですが、暗黙知的にまとまっている情報であれば、手動で情報を追加して、RAGの検索性能を向上させるという選択肢が出てきます。
もちろん人手での対応になるので、限度はありますが、頻出する問い合わせに対する対応であったり、参照情報が少ないユースケースであれば有効な選択肢になるでしょう。
時には、力技で対応することも重要で、RAGの精度向上には直接的にデータを生成・整備するというやり方も選択肢に入ります。
このように、データクレンジングも様々あり、企業でRAGを構築するためには、幅広い選択肢を持っていることが大事です。
状況に応じて、最適な選択をすることが重要で、この領域こそデータサイエンティストの腕の見せ所だと感じます。
まとめ
今回のまとめに移ります。
- RAGの精度向上には参照情報のデータクレンジングが重要である
- 企業が保有しているデータは様々な形式があり、データ整備し、適切に情報を抽出する必要がある
- データをどう整備するかはユースケースによって要件は異なり、データサイエンティストの腕の見せ所
と、いうのが今回のまとめになります。
生成AIは今後のビジネストレンドとなっていく中で、データサイエンティストとしても追随していきたいテーマです。
今後もデータサイエンティストのキャリアについて、発信していこうと思っているので、引き続き、よろしくお願いします。
今回は以上です。ありがとうございました。