

【自己紹介】
#Twitter:@Nurruttan / #YouTube:@Nurruttan
【転職支援サービス】

転職を検討しているデータサイエンティスト向けに【完全無料の】転職支援サービスを実施しています!
詳しくは下記をご覧ください!

【キャリア相談サービス】

キャリアに悩むデータサイエンティスト向けにキャリア相談サービスをやっています!
詳しくは下記をご覧ください!

こんにちは、ぬるったんです。
今回は、Hybrid(ハイブリッド)RAGとはなにか?“従来のRAG”+”GraphRAG”の新手法というテーマで解説していこうと思います。
生成AIを企業で活用するために、欠かせないのが社内情報の参照です。
社内情報を参照させるために、RAGを活用することが多いですが、RAGに関しても多くの手法が提案されています。
今回はRAGの中で、新たに提案されているハイブリッドRAGという技術について解説していこうと思います。
ハイブリッドRAGとは?
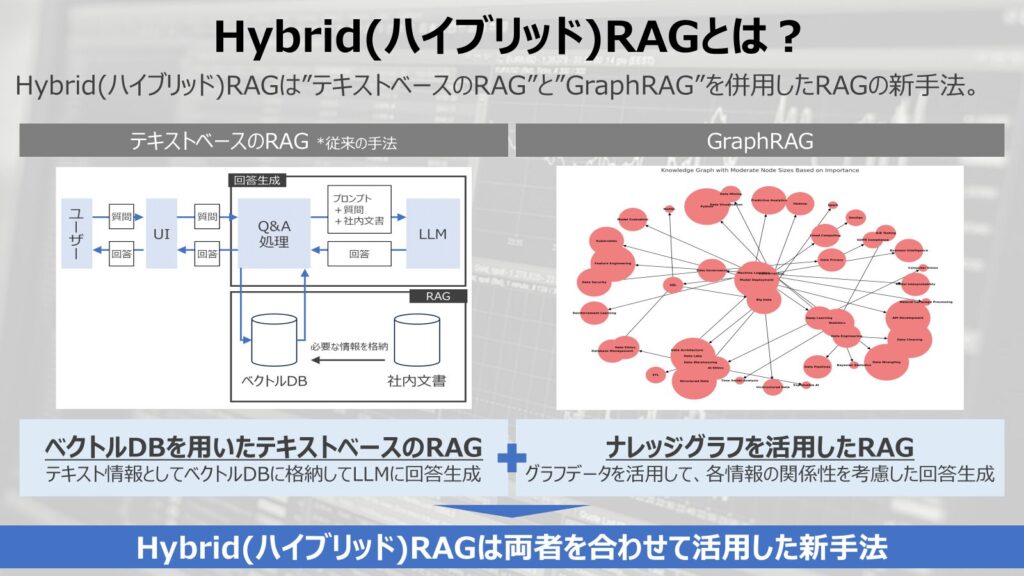
ハイブリッドRAGとは従来のテキストベースのRAGに対して、GraphRAGというRAGを併用して精度を向上させる手法になります。
テキストベースのRAG
従来のテキストベースのRAGでは、参照情報をテキストとして、小分けにチャンクさせた上で、ベクトルデータベースに格納するという手法です。
ユーザーのクエリに対して、関連性の高い情報を検索して、該当する情報を共にLLMが回答を生成することで社内特有の情報をLLMの回答に反映させます。
このテキストベースのRAGが一般的に企業活用の中でも活用が検討されているやり方です。
GraphRAG
ここ最近で新たな手法として出てきたのが、GraphRAGという手法です。
GpaohRAGはナレッジグラフと呼ばれる各ナレッジの関連性を示したグラフデータを扱うことが特徴的で、関連性を考慮して回答を生成させる方法です。
GraohRAGについては、詳細を後述させていただきます。
今回、解説していくハイブリッドRAGはこの2種類の方法を組み合わせて、互いの欠点を補いながら検索性能を向上させる新手法になります。
従来の手法とGraphRAGをハイブリッドに活用することから、ハイブリッドRAGと名がついています。
GraphRAGとは?
ここでGraphRAGについて詳細に解説を挟んでおきます。
GraphRAGは最近注目されてきた技術の一つで従来のRAGの欠点を解決できる手法として、位置付けられています。
ナレッジグラフとは?
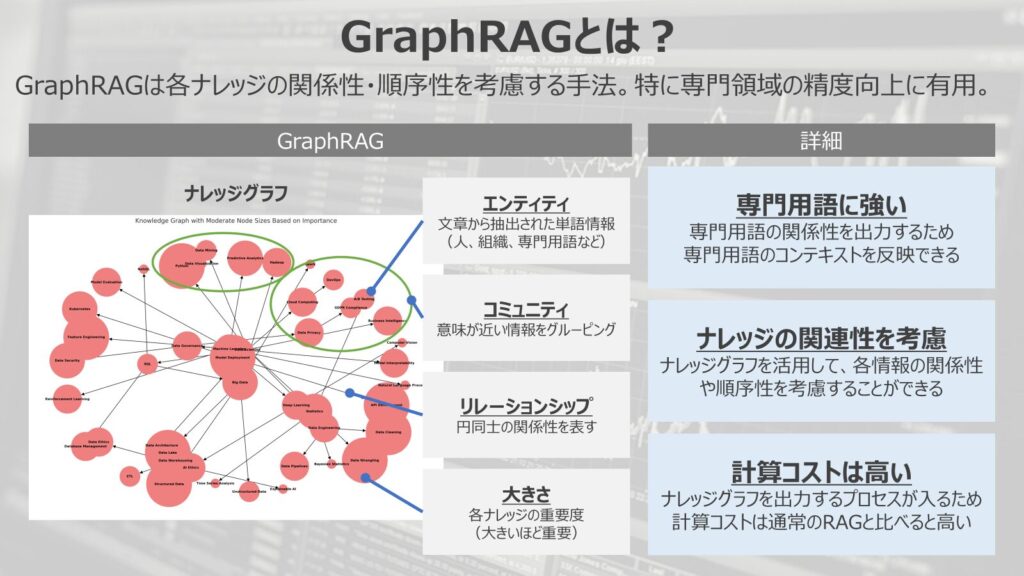
GraphRAGは左の図のようなナレッジグラフというグラフデータを出力してから、情報参照することが特徴的です。
ナレッジグラフとは各ナレッジの関係性や重要度を表したグラフデータであり、対象となるデータの情報分布を表現できるデータになります。
データを表す構成要素としては、
- エンティティ
- コミュニティ
- リレーションシップ
- 大きさ
があります。
エンティティ
エンティティは、文章から抽出された単語情報を指します。
人、場所、組織、専門用語など対象となるデータ内に含まれる単語情報を取り出し、情報の最小単位として扱います。
コミュニティ
コミュニティとは、意味が近いエンティティをグルーピングして類似情報の塊を表現する概念です。
同じコミュニティに属していれば、同じような意味合いの情報として認識されます。
リレーションシップ
リレーションシップとは、各情報の関係性を表す考え方です。
線でつながれている情報同士は互いに関連性がある情報として認識されます。
大きさ
大きさとは、対象データ内での情報の重要性を表します。
円が大きいほど重要度が高い情報として扱われます。
GraphRAGでは対象データに対して、ナレッジグラフと呼ばれる情報の関連性を表すグラフデータを出力した上で、情報検索を行います。
GraphRAGの特徴
この処理を挟むことで、RAGの性能にはいくつかの特徴が生まれます。
専門用語への対応ができる
一つ目が、専門用語への対応ができるという点です。
GraphRAGはナレッジグラフを活用して、ナレッジごとの関係性をマッピングするプロセスが入ります。
そのため、LLMが本来知りえない専門用語同士のコンテキストも上手く把握しながら回答を返すことが出来ます。
ナレッジの関連性を考慮することができる
二つ目が、ナレッジの関連性を考慮することができるという点です。
一点目と少し重複しますが、ナレッジグラフを活用して、各情報の関係性や順序性を考慮することができ、高度な推論が実現できるという点はGraphRAGならではの大きなメリットになります。
計算コストが高くなる
三つ目はネガティブな点ですが、計算コストが高くなります。
対象となるデータをナレッジグラフに処理をしてから、検索をかけるため、従来のRAGと比較して処理プロセスが多くなってしまいます。
そのため、計算コストが高くなるということはGraphRAGならではの特徴になります。
このように、GraphRAGはメリットもありつつ、デメリットも存在する手法であり、状況に応じて適切なアプローチか考える必要があります。
ハイブリッドRAGのメリット・デメリットは?

ここから、ハイブリッドRAGのメリット・デメリットについて解説していきます。
今回は、
- 従来のテキストベースのRAG
- GraphRAG
- ハイブリッドRAG
を比較して、ハイブリッドRAGのメリット・デメリットを解説していきたいと思います。
テキストベースRAG

まず、従来までのテキストベースのRAGについて解説していきます。
テキストベースのRAGは参照情報をテキストとしてベクトルDBに格納して情報検索を行う手法です。
メリット
メリットとしては、
- シンプルでスケーラビリティがある
- 計算コストは低い
- 情報検索の網羅性が高い
と、いった点が挙げられます。
対象となるデータが大規模でもテキストをチャンクして、ベクトル化するシンプルな処理のため、スケーラビリティが担保できます。
シンプルな処理であることから、計算コストは低くなるという特徴があります。
また、情報検索の網羅性という観点では、テキスト情報をすべて検索対象にできることからテキストベースのRAGのメリットとして挙げることができます。
GraphRAGの場合は、事前にナレッジグラフを定義することから、新たな関係性が生まれた場合などに対応がしにくいという側面があります。
つまり、ナレッジグラフに定義されていない情報に関しては、適切に回答ができないということです。
テキストベースの場合であれば、柔軟に該当の検索箇所を探しにいき、該当箇所を参照して柔軟に回答生成することができます。
デメリット
デメリットとしては、
- 各情報の関連性や順序性の精度が低い
- 専門用語に弱い
という、デメリットが挙げられます。
テキストベースの非構造化データを大量に検索することが必要であることから、情報の関係性や順序性を考量することが難しいというのがテキストベースのRAGの欠点です。
回答するために複雑な推論が必要となり、上手く回答を生成することができないというデメリットがあります。
また、LLMが知らない専門用語への対応もテキストベースのRAGでは欠点となるポイントです。
専門用語が多く含まれる文書ではLLMがコンテキストを理解できず、不十分な回答が生成されてしまうというデメリットがあります。
このように、従来のテキストベースのRAGだけでは、専門用語が頻出する領域など、一部対応しきれない領域があるという点が課題となります。
GraphRAG

次に、GraphRAGのメリット・デメリットについて解説していきます。
GraphRAGはナレッジグラフを活用してグラフ情報を基に情報検索を行う手法です。
メリット
メリットとしては、
- 各情報の関連性・順序性を考慮した深い推論ができる
- 専門用語が多い場合でも上手く対応できる
というメリットがあります。
GraphRAGではナレッジグラフを基にして、情報検索を行います。
そのため、各ナレッジ同士の関連性や順序性を正確に把握した上で回答を生成することができ、高度な推論を実現することができます。
また、事前にナレッジグラフで情報の関連性を定義することから、専門用語が頻出するような領域でも各ナレッジの関係性や意味合いを理解した上で回答生成できるというのは大きな特徴です。
デメリット
一方で、デメリットとしては、
- 大規模なデータセットに対して、対応できない場合がある
- 計算コストが高い
- 網羅的な情報検索が弱い
GraphRAGはナレッジグラフを作成する処理を挟みます、ナレッジが膨大になればなるほど大量の処理が必要になってきます。
そのため、莫大なデータセットに対して、活用することはあまり向いていません。
ナレッジグラフを挟む処理があることから計算コストも高くなります。
また、前述したように網羅的な情報検索がやや弱いという点もデメリットとして挙げられます。
GraphRAGを単体として活用することは工夫が必要になるでしょう。
ハイブリッドRAG

最後に、ハイブリッドRAGについて解説していきます。
ハイブリッドRAGは①・②を併用して互いのメリ・デメを補完しながら検索性能を上げる手法です。
メリット
メリットは、テキストベースRAG、GraphRAGの両面が上手く活用できる点がメリットとしてあげられ、
- 網羅的な情報検索ができる
- 各情報の関連性・順序性を考慮した深い推論ができる
- 専門用語が多い場合でも上手く対応できる
という、点が挙げられます。
1点目の網羅的な情報検索ができることは、テキストベースのRAGの特徴を上手く活かしており、GraphRAGの欠点を補うような形になります。
2点目、3点目はGraphRAGの特徴を上手く活かしています。
テキストベースのRAGでは各情報の関連性・順序性を上手く理解できない、専門用語に弱いという特徴があるため、テキストベースのRAGで対応しきれない点をGraphRAGで補うことで精度を向上させます。
このように、テキストベースのRAGとGraphRAGを併用することで互いのメリットを享受できる形になるというのが、ハイブリッドRAGの一番のメリットです。
デメリット
一方で、デメリットとしては
- 大規模なデータセットに対して、対応できない場合がある
- 計算コストが高くなる
- レスポンスが遅くなる
という、ことが挙げられます。両手法のデメリットが合わさる形になります。
GraphRAGを活用するため、大規模なデータセットに対しては、実装することが困難になってしまいます。
また、両方の手法の処理が並列的にかかってくるので、計算コストは高くなります。
結果として、回答生成までのレスポンスもやや低下するというのもデメリットとして発生してしまいます。
このように、各手法でメリット・デメリットは存在します。
ただし、ハイブリッドRAGは対象データの特性が適合すれば、高精度なRAGを構築することができ、精度向上には大きな期待を持つことができます。
ハイブリッドRAGが実用的か?
各手法のメリット・デメリットを踏まえて、ハイブリッドRAGが実用的かどうか?という点について解説していきます。
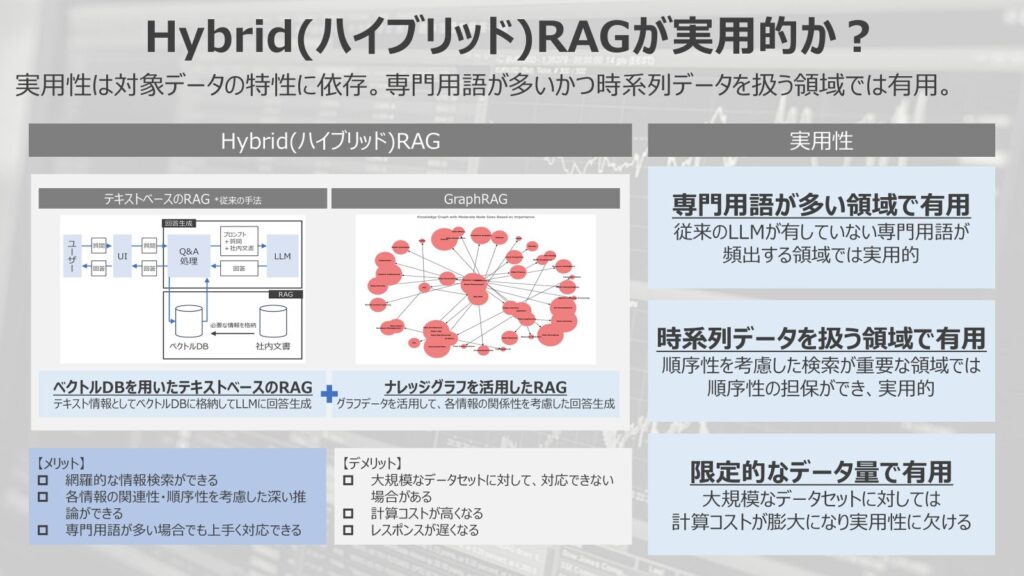
結論、専門用語が多いかつ時系列データを扱う領域では有用であるというのが、私自身の私見になります。
まず、専門用語が頻出する領域であれば、間違いなく有用になります。
従来のテキストベースのRAGだけでは、どうしても専門用語を上手く認識できず、精度が上がらないという課題は発生します。
解決策として、GraphRAGを併用して精度を向上させるというのはよいアプローチです。
テキストベースのRAGで網羅性を担保しつつ、高度な推論が必要な場合はGraphRAG側の情報を参照するというのは期待ができる構成になります。
また、時系列データを扱う領域でも有用になると考えられます。
RAGで参照させたいデータに時系列データが含まれることも多々あります。毎年との○○を読み込ませて、など時系列の順序性を考慮した上で、回答を生成してほしいシーンです。
このような場合では、テキストベースのRAGでは順序性を上手く認識して回答生成することは苦手です。
そこでGraphRAGを併用して順序性を考慮した高度な推論を行わせて、回答を生成させるアプローチが有効になってくると考えられます。
最後に、限定的なデータ量である場合は現実的に利用ができると考えられます。
やはり、ハイブリッドRAGの最大の欠点は計算コストです。
データ量が莫大であれば、計算コストが膨大になってしまうので現実的ではありません。
ある程度限定された領域で、ハイブリッドRAGを構築することが現実的です。
どのようにRAGを構築するかは、対象としているデータの特性に依存するため、幅広い知識を持ってそれぞれの状況に応じて対応していくことが求められていくでしょう。
この対応力がデータサイエンティストとしての腕の見せ所でもあり、幅広く手法を知っておくことが重要になってきます。
まとめ
最後に今回のまとめに移ります。
- “テキストベースのRAG”+”GraphRAG”を合わせたHybridRAGが新手法として提案されている
- 互いの欠点を補う形で検索性能を上げられる手法として期待される
- 対象データによって実用性は異なるので、状況見合いで適切な手法を選択することが重要
と、いうのが今回のまとめになります。
生成AIは今後のビジネストレンドとなっていく中で、データサイエンティストとしても追随していきたいテーマです。
今後もデータサイエンティストのキャリアについて、発信していこうと思っているので、引き続き、よろしくお願いします。
今回は以上です。ありがとうございました。













