【自己紹介】
#Twitter:@Nurruttan / #YouTube:@Nurruttan
【転職支援サービス】

転職を検討しているデータサイエンティスト向けに【完全無料の】転職支援サービスを実施しています!
詳しくは下記をご覧ください!

【キャリア相談サービス】

キャリアに悩むデータサイエンティスト向けにキャリア相談サービスをやっています!
詳しくは下記をご覧ください!

こんにちは、ぬるったんです。
今回は、ベクトル検索とはなにか?RAGの精度向上になぜ必須か?というテーマで解説していきます。
昨今、話題の生成AIですが、データサイエンティストとして、学んでおくべきスキルの一つだと感じています。
生成AIの活用において、広義の意味では「データ活用」であり、データの専門家であるデータサイエンティストが価値を発揮すべき領域であるからです。
今後のデータサイエンティストは生成AIを企業で活用できることが求められていくことは間違いないでしょう。
今回は、生成AI活用で必須の「RAG」を構築する際に必須となる「ベクトル検索」について解説していきます。
YouTube版はこちらをご覧ください。チャンネル登録も合わせてよろしくお願いします。
前提となる「RAG」に関しては、下記の記事を参照ください。

どのようにRAGの精度を向上させるのか?
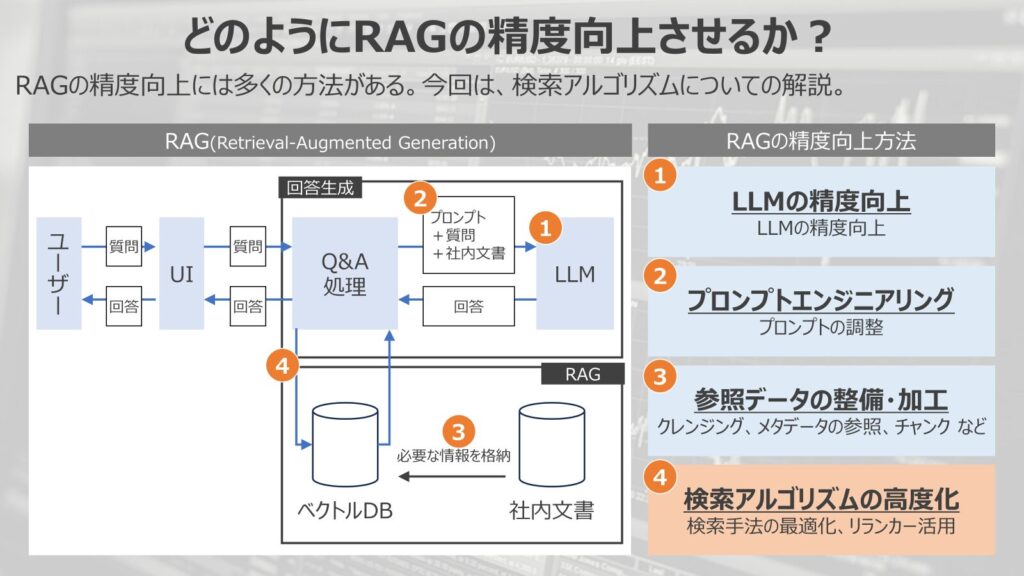
そもそもRAGの精度をどのように向上させるのか?という点を解説していきます。
左の図がRAGの構成になります。
RAGでは、事前にベクトルデータベースに社内情報などの固有情報を参照させて、ユーザーの検索に対して、固有情報を参照させて回答を生成する手法です。
このようなRAGの精度向上には大別して4つ方法が有効です。
- LLMの精度向上
LLM自体の精度を向上させて、RAGの性能を向上させる手法です - プロンプトエンジニアリング
LLMへの指示、プロンプトを調整して、RAGの性能を向上させる方法です - 参照データの整備・加工
参照させるデータのクレンジング、データの参照、チャンクのさせ方など参照データを綺麗にして、RAGの性能を向上させる方法です - 検索アルゴリズムの高度化
検索手法を最適化、リランカーの導入などにより、情報への検索性能を上げて、RAGの性能を向上させる方法です
今回は、この4つの中でも最後の検索アルゴリズムの高度化に焦点を当てた内容になっています。
ベクトル検索とはなにか?

ここからベクトル検索の解説に移っていきます。
ベクトル検索は画像やテキストを数値化し、類似度を算出して情報の関連度を検索する手法です。
ベクトル検索では単語の埋め込み(embeddding)をまずは行います。
単語の埋め込みとは、単語を数値化して、計算できる形に変換します。この数値化するという処理をベクトル化と呼び、数値化された情報をベクトルと呼びます。
このように数値化することで、計算が可能となり、各ベクトルの類似度が計算できるようになります。
代表例がコサイン類似度と呼ばれる指標です。イメージでは単語ごとの角度のようなイメージになります。(正確には、多次元空間になるので、正確な表現ではありません)
一番のメリットは単語や文章を数値化することで、単語・文章ごとの類似度が計算できることです。
単語・文章の類似度が計算できれば、検索の際に、関連性の高い情報を抽出することができ、有能な検索アルゴリズムを構築することができます。
このように、ベクトル検索は、関連性の高い情報を検索するために有能な手法として、レコメンドシステムなどでも用いられる自然言語処理の手法です。
なぜベクトル検索がRAGに重要なのか?
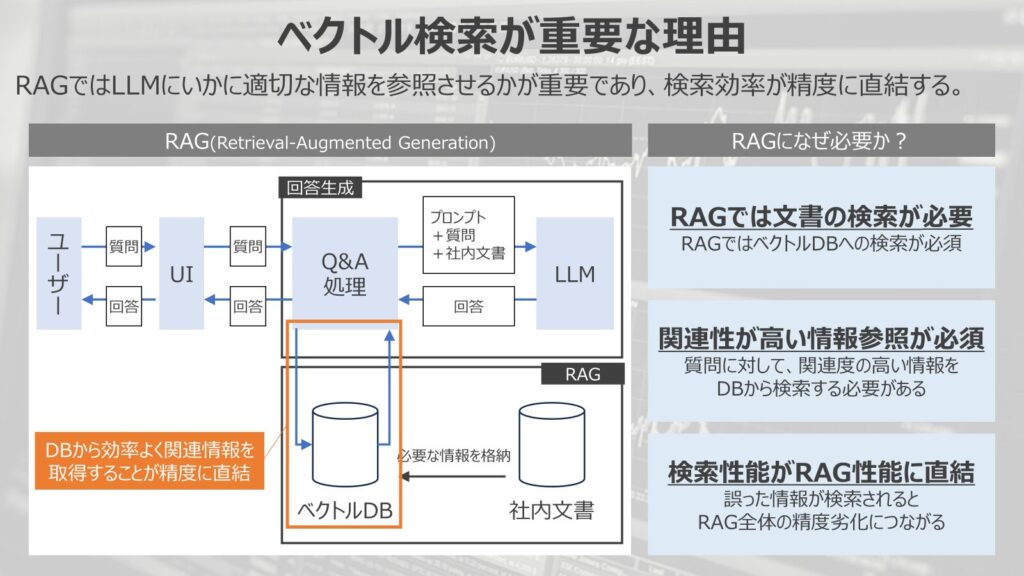
では、なぜベクトル検索がRAGに重要なのか?という点について解説していきます。
端的に言うと、RAGではLLMにいかに適切な情報を参照させるかが重要であるからです。
検索効率がRAGの回答精度に直結するため、検索性能が重要となってきます。
そもそもRAGを構築するメリットとしては、LLMが知らない固有の情報を入力して、固有情報を踏まえた回答を生成させることです。
そのため、正しく固有情報を検索して、情報を取得することがなによりも重要になります。
LLMに正しい情報を参照させることができなければ、いかにLLMが性能が高くても知らないものは答えることができません。
だからこそ、ユーザーの質問に対して、関連性が高い情報を取得することがRAGの性能に直結します。
事前に固有情報を格納したベクトルデータベースからいかに効率よく、情報を引っ張ってくるか?という点で検索アルゴリズムが重要になります。
このような理由から、ベクトル検索がRAGに重要な要素になってきます。
ベクトル検索の種類

最後に、ベクトル検索の種類についても簡単に解説していきます。
一部、ベクトル検索以外の検索アルゴリズムも含んでいますが、RAGで活用される検索アルゴリズムはいくつかあります。
- キーワード検索
文字列の一致やパターンマッチングで検索する手法 - ベクトル検索
ベクトル毎の類似度を計算して、文書間の類似度を計算して検索する手法 - ハイブリッド検索
「キーワード検索」と「ベクトル検索」を組み合わせた検索手法 - セマンティック検索
「キーワード検索」の結果を再ランク付けをして、検索性能を高める手法 - ハイブリッド検索+セマンティックランク付け
「ハイブリッド検索」の結果に対して、再ランク付けをして、検索性能を高める手法
と、いうのが、よく目にする手法です。
基本となる手法は「キーワード検索」と「ベクトル検索」であり、これらを上手く組み合わせて検索性能の向上を図ることが多いです。
また、リランカーと呼ばれる「再ランク付け」をすることで、検索性能を高める手法もあります。
これは、一度「キーワード検索」、「ベクトル検索」、「ハイブリッド検索」を行った上で、上位○○件の情報に限定したものに対して、再度類似度を計算して、関連性を再ランク付けする手法です。
今回は簡易的な説明にとどめますが、リランカーにより、「再ランク付け」を行い、検索性能を向上させるやり方も高級な検索アルゴリズムとして存在します。
このように、複数の検索アルゴリズムがありますが、各検索アルゴリズムごとに検索性能と計算コストのトレードオフが発生します。
一般的には検索性能が高いほど、計算コストがかかります。
性能はよいが、応答性が悪くなったり、費用がかさむなどといったことが起きます。
そのため、どのような場合でも検索性能だけを追い求めていればいい、という訳でなく、それぞれの利用用途や検索対象などにより最適な選択をする必要があるというのが、難しいポイントです。
RAG構成でも、参照する情報が少なくて、LLMの生成能力に期待をするような使い方であれば、検索アルゴリズムは簡易的なもので問題ありません。
一方で、大量のドキュメントを参照させて、検索システムとしてLLMを使いたいという場合は、検索アルゴリズムにこだわる必要があります。
このように、利用用途に応じて、最適な選択をすることが求められ、企業で活用する場合は社内のコミュニケーションなどが煩雑化し、難しくなるシーンも多々あります。
生成AIの活用を推進していくためには、データサイエンティストとして、幅広い知識を持った上で、適切な判断を仰ぐ能力も重要になってきます。
まとめ
と、いうところで、今回はベクトル検索について解説していきました。
- ベクトル検索は単語・文書を数値化して、関連性を検索するアルゴリズム
- RAGの精度向上では参照情報の検索が重要で、検索性能がRAGの精度に直結する
- 検索アルゴリズムは複数あり、それぞれで検索性能と計算コストでトレードオフが発生するため、用途に応じて最適な選択が必要
と、いうのが今回のまとめになります。
生成AIのスキルは今後のデータサイエンティストのキャリア構築には非常に重要なスキルになってきます。
今後も生成AIの企業活用というテーマで発信していこうと思います。
今回は以上です。ありがとうございました。